
Seção 1 - Visão geral e preparação
Aula 12 a 14 - Softwares Complementares / Conectando-se ao banco de dadosNotepad++: Editor de textos simples com opções de linguagens.
brModelo: Um programa gratuito para modelagem de dados.
StarUML: Outro programa para modelagem de DB que inclusive gera scripts SQL.
Ao iniciar o MySQL podemos consultar o local onde são armazenados os arquivos de dados com o comando:
SHOW variables LIKE 'datadir';
Seção 2 - Um pouco de teoria, sem esquecer a prática!
Aula 15 - Arquiterura de software
Aula 16 - Modelagem lógica e física
Um BD surge da necessidade dos usuários de acessarem
dados e informações.
A modelagem do BD é feita para que os dados que devem ser armazenados. O início da modelagem é feita por um documento de requisitos, que deve ser analizado por todas as pessoas que terão acesso as informações e que avaliam quais dados são necessários.
Abaixo um modelo de Requisitos de Software:
Com base nessas informações podemos definir o escopo do projeto. A definição de um escopo permite que se delimite o que deve ser inserido no projeto e consequentemente o tempo gasto na sua construção.
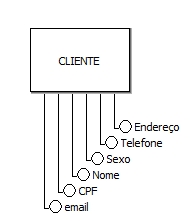
Com isso iniciamos a modelagem básica. Primeiro veremos quais as informações necessárias, no nosso caso para uma tabela de clientes. Aqui definimos os campos necessários para o nosso banco:
Modelagem Conceitual: a fase mais primitiva, que engloba a coleta de informações para a implementação do que será incluido no BD.
Modelagem Lógica: a construção de modelos (com ou sem aplicativos de modelagem) que permite visualizar o que e como será implementado.
As fases 01 e 02 (conceitual e lógica) são geralmente executadas pelo AD que é quem conhece os dados da empresa, sabendo quais as tabelas que já existem e quais os dados já estão disponíveis no negócio, ou seja, é quem conhece as informações e não necessariamente a programação do BD.
Já a fase 3, a Modelagem Física é geralmente implementada pelo DBA pois lida diretamente com os scripts no BD.
A modelagem básica também deve receber a tipagem de dados de cada campo.
Feito isso podemos criar o modelo no aplicativo de modelagem. Utilizamos o brModelo no curso.
A tabela é criada como Entidade e as colunas são os Atributos
A modelagem do BD é feita para que os dados que devem ser armazenados. O início da modelagem é feita por um documento de requisitos, que deve ser analizado por todas as pessoas que terão acesso as informações e que avaliam quais dados são necessários.
Abaixo um modelo de Requisitos de Software:
O cliente Tera Comércio de Produtos S.A, solicitou a
modelagem de um banco de dados para cadastro dos
seus clientes. A função da Unidados é a análise dos
requisitos junto aos usuários para a correta
construção do produto. O cliente deseja que
inicialmente os scripts sejam construídos para o
Banco de Dados MySQL, porém, posteriormente pode
haver mudança no ambiente e consequentemente
adaptação dos scripts para outros produtos de SGBD.
O cliente não quer nenhuma informação relativa à
vendas ou estoque, desejando somente as informações
primárias de Clientes.
Com base nessas informações podemos definir o escopo do projeto. A definição de um escopo permite que se delimite o que deve ser inserido no projeto e consequentemente o tempo gasto na sua construção.
Com isso iniciamos a modelagem básica. Primeiro veremos quais as informações necessárias, no nosso caso para uma tabela de clientes. Aqui definimos os campos necessários para o nosso banco:
Modelagem básica
Cliente
Nome - caracter(30)
CPF - numerico(11)
Email - caracter(30)
Telefone - caracter(30)
Endereço - caracter(100)
Sexo - caracter(1)
A modelagem de um BD passa por tres fases: Cliente
Nome - caracter(30)
CPF - numerico(11)
Email - caracter(30)
Telefone - caracter(30)
Endereço - caracter(100)
Sexo - caracter(1)
Modelagem Conceitual: a fase mais primitiva, que engloba a coleta de informações para a implementação do que será incluido no BD.
Modelagem Lógica: a construção de modelos (com ou sem aplicativos de modelagem) que permite visualizar o que e como será implementado.
As fases 01 e 02 (conceitual e lógica) são geralmente executadas pelo AD que é quem conhece os dados da empresa, sabendo quais as tabelas que já existem e quais os dados já estão disponíveis no negócio, ou seja, é quem conhece as informações e não necessariamente a programação do BD.
Já a fase 3, a Modelagem Física é geralmente implementada pelo DBA pois lida diretamente com os scripts no BD.
A modelagem básica também deve receber a tipagem de dados de cada campo.
Feito isso podemos criar o modelo no aplicativo de modelagem. Utilizamos o brModelo no curso.
A tabela é criada como Entidade e as colunas são os Atributos
Aula 17 - Modelagem física

A Modelagem Física é a transcrição da
Modelagem Lógica para o script SQL.
Para isso primeiramente criamos o BD e em seguida a tabela conforme o modelo.
Para a modelagem física o ideal é criar o script em um aplicativo (ou pelo Workbench) para depois enviar para o MySQL em linha de comando. O Notepad++ permite a digitação dos scripts com um pequeno emmet de comandos.
Criamos em seguida o DATABASE e a TABLE. Aqui iniciamos a utilização de tipagem e verificamos que a importancia de uma tipagem correta auxilia na área de tunning pois facilita a melhora de performance do DB. As áreas de atuação em Bancos de Dados é composta por diversos profissionais entre eles: AD, DBA, Tunning, BI e Data Science. Além do AD e do DBA, o profisisonal de Tunning cuida da performance do DB, o BI analisa os dados recebidos e o Data Science faz aas previsões futuras com os dados obtidos.
A montagem do banco foi feita seguindo o seguinte script:
Para isso primeiramente criamos o BD e em seguida a tabela conforme o modelo.
Para a modelagem física o ideal é criar o script em um aplicativo (ou pelo Workbench) para depois enviar para o MySQL em linha de comando. O Notepad++ permite a digitação dos scripts com um pequeno emmet de comandos.
Criamos em seguida o DATABASE e a TABLE. Aqui iniciamos a utilização de tipagem e verificamos que a importancia de uma tipagem correta auxilia na área de tunning pois facilita a melhora de performance do DB. As áreas de atuação em Bancos de Dados é composta por diversos profissionais entre eles: AD, DBA, Tunning, BI e Data Science. Além do AD e do DBA, o profisisonal de Tunning cuida da performance do DB, o BI analisa os dados recebidos e o Data Science faz aas previsões futuras com os dados obtidos.
A montagem do banco foi feita seguindo o seguinte script:
/* Iniciando a modelagem física */
/* Criação do Banco de Dados */
CREATE DATABASE PROJETO;
CREATE DATABASE EXEMPLO;
/* Conectando-se ao Banco */
USE PROJETO;
/* Criando a tabela clientes */
CREATE TABLE cliente(
NOME VARCHAR(30),
SEXO CHAR(1),
EMAIL VARCHAR(30),
CPF INT(11),
TELEFONE VARCHAR(30),
ENDERECO VARCHAR (100)
);
/* Verificando as tabelas do banco */
SHOW TABLES;
/* Descobrindo como é a estrutura de uma tabela */
DESC cliente;
Notar que o comando DESC tem a mesma função que
o comando EXPLAIN ou seja descrever os campos
de uma tabela.
/* Criação do Banco de Dados */
CREATE DATABASE PROJETO;
CREATE DATABASE EXEMPLO;
/* Conectando-se ao Banco */
USE PROJETO;
/* Criando a tabela clientes */
CREATE TABLE cliente(
NOME VARCHAR(30),
SEXO CHAR(1),
EMAIL VARCHAR(30),
CPF INT(11),
TELEFONE VARCHAR(30),
ENDERECO VARCHAR (100)
);
/* Verificando as tabelas do banco */
SHOW TABLES;
/* Descobrindo como é a estrutura de uma tabela */
DESC cliente;
Aula 18 a 19 - Comparando CHAR e VARCHAR / Comparando
ENUM e numéricos
A Tipagem de tabelas de Bancos de Dados é
fundamental para o desempenho de um DB. Em um DB podemos
utilizar campos para Caracteres Literais
CHAR e VARCHAR, Numeros
INT e FLOAT,
Fotos e Documentos BLOB e
Textos Extensos TEXT.
Em um DB cada caractere vale 1 byte. Quando utilizamos um campo de caractere do tipo CHAR definimos uma quantidade fixa de caracteres. Quando não utilizamos todos os caracteres definidos os bytes livres são preenchidos por espaço. Já no VARCHAR utilizamos apenas a quantidade de dados armazenados descartando os bytes vazios. Entretanto o CHAR é ligeiramente mais performático portanto quando utilizamos campos com uma quantidade fixa de caracteres podemos definir como CHAR.
O ENUM é um tipo específico do MySQL. Ele enumera valores específicos para determinado campo e funciona como uma combobox limitando as opções de inserção.
Os tipo numéricos podem ser INT para numeros inteiros e FLOAT para números reais. Nos tipo FLOAT(x,y) 'x' representa o número total de digitos de um numero e 'y' define quantos desses números são reservados para casas decimais. Dessa forma um FLOAT(5,2) terá a seguinte saida: XXX,YY.
O tipo INT permite até 11 digitos. Por isso em alguns casos de campos numéricos onde não serão realizados cálculos é mais interessante utilizar dados tipo CHAR.
Em um DB cada caractere vale 1 byte. Quando utilizamos um campo de caractere do tipo CHAR definimos uma quantidade fixa de caracteres. Quando não utilizamos todos os caracteres definidos os bytes livres são preenchidos por espaço. Já no VARCHAR utilizamos apenas a quantidade de dados armazenados descartando os bytes vazios. Entretanto o CHAR é ligeiramente mais performático portanto quando utilizamos campos com uma quantidade fixa de caracteres podemos definir como CHAR.
O ENUM é um tipo específico do MySQL. Ele enumera valores específicos para determinado campo e funciona como uma combobox limitando as opções de inserção.
Os tipo numéricos podem ser INT para numeros inteiros e FLOAT para números reais. Nos tipo FLOAT(x,y) 'x' representa o número total de digitos de um numero e 'y' define quantos desses números são reservados para casas decimais. Dessa forma um FLOAT(5,2) terá a seguinte saida: XXX,YY.
O tipo INT permite até 11 digitos. Por isso em alguns casos de campos numéricos onde não serão realizados cálculos é mais interessante utilizar dados tipo CHAR.
Seção 3 - Elevando o nível - Comandos que voce não pode deixar de saber
Aula 21 - Tipos Nulos e InteirosUtilizei o nome da tabela em letras maiúsculas, porém na aula foi utilizado minúscula. Para alterar o nome da tabela utilizei o comando:
RENAME TABLE CLIENTE to cliente;
Para incluir dados em uma tabela, utilizamos o comando INSERT INTO nome_da_tabela.... Quando inserimos dados em uma tabela, os valores do tipo string deve ser informado entre ' '. Os valores do tipo numérico são declarados sem as aspas. Devemos utilizar campos numéricos preferencialmente nas situações em que precisamos executar operações matemáticas.
Podemos inserir dados utilizando algumas sintaxes:
Omitindo colunas: nesse caso devemos passar todos os valores e na ordem em que estão definido na tabela.
Colocando as colunas: nesse caso declaramos inicialmente quais as colunas que serão preenchidas e em seguida passamos os valores na sequencia que declaramos inicialmente. Nesse caso podemos inclusive omitir colunas (desde que admmitam valores nulos).
Insert compacto: esse modo exclusivo do MySQL permite que façamos a inserção de registros utilizando um único comando, listando cada registro entre parenteses.
Note que quando definimos o campo INT(11) o valor máximo no campo não será '99999999999' mas sim o valor máximo que o tipo aceita (-2147483648 a 2147483647). Na configuração da aula o MySQL retornou um erro. No meu BD ele converteu o '99999999999' para '2147483647'. Abaixo as colunas inseridas:
/* FORMA 01 - OMITINDO AS COLUNAS */
INSERT INTO CLIENTE VALUES('JOAO', 'M', '[email protected]',988638273, '22923110','MAIA LACERDA - ESTACIO - RIO DE JANEIRO - RJ');
INSERT INTO CLIENTE VALUES('CELIA', 'F', '[email protected]',541521456, '25078869','RIACHUELO - CENTRO - RIO DE JANEIRO - RJ');
INSERT INTO CLIENTE VALUES('JORGE', 'M', NULL, 885755896, '58748895','OSCAR CURY - BOM RETIRO - PATOS DE MINAS - MG');
/* FORMA 02 - COLOCANDO AS COLUNAS */
INSERT INTO CLIENTE(NOME,SEXO,ENDERECO,TELEFONE,CPF) VALUES('LILIAN', 'F', 'SENADOR SOARES - TIJUCA - RIO DE JANEIRO - RJ', '947785696', 887774856);
/* FORMA 03 - INSERT COMPACTO - SOMENTE MYSQL */
INSERT INTO CLIENTE VALUES('ANA', 'F', '[email protected]', 85548962, '548556985', 'PRES ANTONIO CARLOS - CENTRO - SAO PAULO - SP'),('CARLA', 'F', '[email protected]', 7745828,'66587458','SAMUEL SILVA - CENTRO - BELO HORIZONTE - MG');
/* INSERT COM ESTOURO DO INT */
INSERT INTO CLIENTE(NOME,SEXO,ENDERECO,TELEFONE,CPF) VALUES('CLARA', 'F', 'SENADOR SOARES - TIJUCA - RIO DE JANEIRO - RJ', '883665843', 99999999999);
INSERT INTO CLIENTE VALUES('JOAO', 'M', '[email protected]',988638273, '22923110','MAIA LACERDA - ESTACIO - RIO DE JANEIRO - RJ');
INSERT INTO CLIENTE VALUES('CELIA', 'F', '[email protected]',541521456, '25078869','RIACHUELO - CENTRO - RIO DE JANEIRO - RJ');
INSERT INTO CLIENTE VALUES('JORGE', 'M', NULL, 885755896, '58748895','OSCAR CURY - BOM RETIRO - PATOS DE MINAS - MG');
/* FORMA 02 - COLOCANDO AS COLUNAS */
INSERT INTO CLIENTE(NOME,SEXO,ENDERECO,TELEFONE,CPF) VALUES('LILIAN', 'F', 'SENADOR SOARES - TIJUCA - RIO DE JANEIRO - RJ', '947785696', 887774856);
/* FORMA 03 - INSERT COMPACTO - SOMENTE MYSQL */
INSERT INTO CLIENTE VALUES('ANA', 'F', '[email protected]', 85548962, '548556985', 'PRES ANTONIO CARLOS - CENTRO - SAO PAULO - SP'),('CARLA', 'F', '[email protected]', 7745828,'66587458','SAMUEL SILVA - CENTRO - BELO HORIZONTE - MG');
/* INSERT COM ESTOURO DO INT */
INSERT INTO CLIENTE(NOME,SEXO,ENDERECO,TELEFONE,CPF) VALUES('CLARA', 'F', 'SENADOR SOARES - TIJUCA - RIO DE JANEIRO - RJ', '883665843', 99999999999);
Aula 22 - Conhecendo as projeções
O comando SELECT é universal em todos os SGBDs.
Ele faz parte de um conjunto de operações de
fundamentais para manipulação de BDs: seleção,
projeção e junção.
O SELECT é responsável pela projeção. Com ele podemos mostrar qualquer coisa na tela. O comando SHOW TABLES é exclusivo do MySQL e na verdade faz um apontamento utilizando o SELECT para um dicionário de dados. Como visto podemos utilizar a projeção com SELECT para mostrar qualquer texto na interface que recebe os dados. Isso é especialmente útil para quando precisamos definir ALIAS para algumas colunas.
O SELECT portanto não serve apenas para recuperar dados mas sim para construir projeções de informações conforme programado. Veja que no exemplo abaixo projetamos dados sem a necessidade de consultas ao BD.
SELECT NOW() AS DATA_HORA, 'FELIPE MAFRA' AS PROFESSOR;
Para recuperar dados de tabelas utilizamos o SELECT com os campos que queremos consultar.
SELECT NOME, SEXO, EMAIL FROM CLIENTE;
Podemos renomear na exibição o título de um campo criando um Alias para ele:
SELECT NOME AS CLIENTE, SEXO, EMAIL FROM CLIENTE;
Podemos ordenar os dados como quisermos.
A utilização da operação SELECT * FROM tabela deve ser evitada pois ela traz todos os dados da tabela, desperdiçando tráfego e performance com dados desnecessários. Entre outros problemas o uso do '*' faz um full scan da tabela ignorando qualquer indexação feita para otimização das buscas.
Um exemplo de como mesclar dados da tabela com dados de projeção sem origem no BD:
SELECT SEXO, EMAIL, ENDERECO, NOME, NOW() AS DATA_HORA FROM CLIENTE;
O SELECT é responsável pela projeção. Com ele podemos mostrar qualquer coisa na tela. O comando SHOW TABLES é exclusivo do MySQL e na verdade faz um apontamento utilizando o SELECT para um dicionário de dados. Como visto podemos utilizar a projeção com SELECT para mostrar qualquer texto na interface que recebe os dados. Isso é especialmente útil para quando precisamos definir ALIAS para algumas colunas.
SELECT NOW();
SELECT 'FELIPE MAFRA';
SELECT 'BANCO DE DADOS';
No exemplo acima o NOW() é uma função que exibe
a data e hora atual. SELECT 'FELIPE MAFRA';
SELECT 'BANCO DE DADOS';
O SELECT portanto não serve apenas para recuperar dados mas sim para construir projeções de informações conforme programado. Veja que no exemplo abaixo projetamos dados sem a necessidade de consultas ao BD.
SELECT NOW() AS DATA_HORA, 'FELIPE MAFRA' AS PROFESSOR;
Para recuperar dados de tabelas utilizamos o SELECT com os campos que queremos consultar.
SELECT NOME, SEXO, EMAIL FROM CLIENTE;
Podemos renomear na exibição o título de um campo criando um Alias para ele:
SELECT NOME AS CLIENTE, SEXO, EMAIL FROM CLIENTE;
Podemos ordenar os dados como quisermos.
A utilização da operação SELECT * FROM tabela deve ser evitada pois ela traz todos os dados da tabela, desperdiçando tráfego e performance com dados desnecessários. Entre outros problemas o uso do '*' faz um full scan da tabela ignorando qualquer indexação feita para otimização das buscas.
Um exemplo de como mesclar dados da tabela com dados de projeção sem origem no BD:
SELECT SEXO, EMAIL, ENDERECO, NOME, NOW() AS DATA_HORA FROM CLIENTE;
Aula 23 - Seleções
Filtros em SQL podem ser feitos pela projeção
para as colunas e através de seleção quando o aplicamos
nas linhas.
Como na projeção utilizamos o SELECT para a seleção utilizamos o WHERE.
Fazemos seleções com WHERE declarando o campo que queremos consultar e o valor exato que desejamos que filtre os dados. Quando queremos que o filtro seja mais abrangente, ou seja, consiga recuperar valores incompletos ou aproximados utilizamos a expressão LIKE e o '%'(coringa). O coringa pode ser utilizado no inicio, no final ou em ambos os lados da expressão procurada. Caso queiramos restringir a busca com o coringa podemos utilizar o '_' para definir o numero de caracteres coringa até ou após o termo procurado.
Como na projeção utilizamos o SELECT para a seleção utilizamos o WHERE.
Fazemos seleções com WHERE declarando o campo que queremos consultar e o valor exato que desejamos que filtre os dados. Quando queremos que o filtro seja mais abrangente, ou seja, consiga recuperar valores incompletos ou aproximados utilizamos a expressão LIKE e o '%'(coringa). O coringa pode ser utilizado no inicio, no final ou em ambos os lados da expressão procurada. Caso queiramos restringir a busca com o coringa podemos utilizar o '_' para definir o numero de caracteres coringa até ou após o termo procurado.
Seção 4 - Exercício de revisão
Aula 24 - Exercício Livraria
O nosso cliente solicitou uma tabela para armazenar
os livros que são comercializados pela empresa. A
solicitação é somente para livros e não há a
necessidade de realizar busca em outras tabelas.
Hoje há um funcionário de vendas que tem uma tabela
do Excel para guardar esses registros, mas as buscas
estão ficando complexas. Decidiu-se então criar um
banco de dados separado para esse funcionário. Após
a criação da tabela, deveremos entregar algumas
queries prontas para que sejam enviadas para o
programador. As queries são as seguintes: 1 – Trazer
todos os dados. 2 – Trazer o nome do livro e o nome
da editora 3 – Trazer o nome do livro e a UF dos
livros publicados por autores do sexo masculino. 4 -
Trazer o nome do livro e o número de páginas dos
livros publicados por autores do sexo feminino. 5 –
Trazer os valores dos livros das editoras de São
Paulo. 6 – Trazer os dados dos autores do sexo
masculino que tiveram livros publicados por São
Paulo ou Rio de Janeiro (Questão Desafio).
Aula 25 a 27 - Correção Parte 01 / Correção Parte 02 /
Correção Parte 03
Correção do execício anterior. Execto pela quantidade de
caracteres tudo ficou igual.
/* Cria BD */
CREATE DATABASE LIVRARIA;
USE LIVRARIA;
/* Cria tabela */
CREATE TABLE LIVROS (
TITULO VARCHAR(100),
NUMERO_PAGINAS INT,
AUTOR VARCHAR(50),
SEXO_AUTOR CHAR(1),
EDITORA VARCHAR(30),
ESTADO CHAR(2),
PRECO FLOAT(10,2),
ANO_PUB INT(4)
);
/* Insere dados */
INSERT INTO LIVROS (TITULO, AUTOR, SEXO_AUTOR, NUMERO_PAGINAS, EDITORA, PRECO, ESTADO, ANO_PUB) VALUES('Cavaleiro Real', 'Ana Claudia', 'F', 465, 'Atlas', 49.9, 'RJ', 2009);
INSERT INTO LIVROS (TITULO, AUTOR, SEXO_AUTOR, NUMERO_PAGINAS, EDITORA, PRECO, ESTADO, ANO_PUB) VALUES('SQL para leigos', 'Joao Nunes', 'M', 450, 'Addison', 98, 'SP', 2018),('Receitas Caseiras', 'Celia Tavares', 'F', 210, 'Atlas',45,'RJ',2008),('Pessoas Efetivas', 'Eduardo Santos', 'M', 390, 'Beta', 78.99,'RJ',2018);
INSERT INTO LIVROS (TITULO, AUTOR, SEXO_AUTOR, NUMERO_PAGINAS, EDITORA, PRECO, ESTADO, ANO_PUB) VALUES('Habitos Saudaveis', 'Eduardo Santos', 'M', 630, 'Beta',150.98,'RJ',2019),('A Casa Marrom','Hermes Macedo', 'M', 250,'Bubba',60,'MG',2016),('Estacio Querido', 'Geraldo Francisco', 'M', 310, 'Insignia', 100,'ES',2011);
INSERT INTO LIVROS (TITULO, AUTOR, SEXO_AUTOR, NUMERO_PAGINAS, EDITORA, PRECO, ESTADO, ANO_PUB) VALUES('Pra sempre amigas', 'Leda Silva', 'F', 510, 'Insignia', 78.98, 'ES', 2011),('Copas Inesqueciveis', 'Marco Alcantara', 'M', 200, 'Larson', 130.98, 'RS', 2018),('O poder da mente', 'Clara Mafra', 'F', 120, 'Continental', 56.58,'RS',2017);
/* Query solicitadas */
SELECT TITULO, NUMERO_PAGINAS, AUTOR, SEXO_AUTOR, EDITORA, ESTADO, PRECO, ANO_PUB FROM LIVROS;
SELECT TITULO, EDITORA FROM LIVROS;
SELECT TITULO, ESTADO FROM LIVROS WHERE SEXO_AUTOR='M';
SELECT TITULO, NUMERO_PAGINAS FROM LIVROS WHERE SEXO_AUTOR='F';
SELECT PRECO AS VALOR FROM LIVROS WHERE ESTADO='SP';
SELECT AUTOR, SEXO_AUTOR FROM LIVROS WHERE SEXO_AUTOR='M' AND (ESTADO='SP' OR ESTADO='RJ');
CREATE DATABASE LIVRARIA;
USE LIVRARIA;
/* Cria tabela */
CREATE TABLE LIVROS (
TITULO VARCHAR(100),
NUMERO_PAGINAS INT,
AUTOR VARCHAR(50),
SEXO_AUTOR CHAR(1),
EDITORA VARCHAR(30),
ESTADO CHAR(2),
PRECO FLOAT(10,2),
ANO_PUB INT(4)
);
/* Insere dados */
INSERT INTO LIVROS (TITULO, AUTOR, SEXO_AUTOR, NUMERO_PAGINAS, EDITORA, PRECO, ESTADO, ANO_PUB) VALUES('Cavaleiro Real', 'Ana Claudia', 'F', 465, 'Atlas', 49.9, 'RJ', 2009);
INSERT INTO LIVROS (TITULO, AUTOR, SEXO_AUTOR, NUMERO_PAGINAS, EDITORA, PRECO, ESTADO, ANO_PUB) VALUES('SQL para leigos', 'Joao Nunes', 'M', 450, 'Addison', 98, 'SP', 2018),('Receitas Caseiras', 'Celia Tavares', 'F', 210, 'Atlas',45,'RJ',2008),('Pessoas Efetivas', 'Eduardo Santos', 'M', 390, 'Beta', 78.99,'RJ',2018);
INSERT INTO LIVROS (TITULO, AUTOR, SEXO_AUTOR, NUMERO_PAGINAS, EDITORA, PRECO, ESTADO, ANO_PUB) VALUES('Habitos Saudaveis', 'Eduardo Santos', 'M', 630, 'Beta',150.98,'RJ',2019),('A Casa Marrom','Hermes Macedo', 'M', 250,'Bubba',60,'MG',2016),('Estacio Querido', 'Geraldo Francisco', 'M', 310, 'Insignia', 100,'ES',2011);
INSERT INTO LIVROS (TITULO, AUTOR, SEXO_AUTOR, NUMERO_PAGINAS, EDITORA, PRECO, ESTADO, ANO_PUB) VALUES('Pra sempre amigas', 'Leda Silva', 'F', 510, 'Insignia', 78.98, 'ES', 2011),('Copas Inesqueciveis', 'Marco Alcantara', 'M', 200, 'Larson', 130.98, 'RS', 2018),('O poder da mente', 'Clara Mafra', 'F', 120, 'Continental', 56.58,'RS',2017);
/* Query solicitadas */
SELECT TITULO, NUMERO_PAGINAS, AUTOR, SEXO_AUTOR, EDITORA, ESTADO, PRECO, ANO_PUB FROM LIVROS;
SELECT TITULO, EDITORA FROM LIVROS;
SELECT TITULO, ESTADO FROM LIVROS WHERE SEXO_AUTOR='M';
SELECT TITULO, NUMERO_PAGINAS FROM LIVROS WHERE SEXO_AUTOR='F';
SELECT PRECO AS VALOR FROM LIVROS WHERE ESTADO='SP';
SELECT AUTOR, SEXO_AUTOR FROM LIVROS WHERE SEXO_AUTOR='M' AND (ESTADO='SP' OR ESTADO='RJ');
Seção 5 - Lógica de Predicados
Aula 28 a 30 - A Tabela Verdade / Operadores Lógicos - Prática / Performance com Operadores LógicosFizemos algumas querys com os operadores lógicos:
SELECT NOME, SEXO, ENDERECO FROM CLIENTE WHERE SEXO = 'M' OR ENDERECO LIKE '%RJ'; SELECT NOME, SEXO, ENDERECO FROM CLIENTE WHERE SEXO = 'F' AND ENDERECO LIKE '%ESTACIO%'; Para melhorar as querys temos alguma funções de agregação. Essas funções tem por objetivo realizar operações de filtragem e contagem dos dados de modo a otimizar os filtros.
COUNT(): retorna o numero de ocorrencias em determinada seleção.
SELECT COUNT(*) AS 'Quantidade de registros da tabela cliente' FROM CLIENTE; GROUP BY: faz o agrupamento da contagem de acordo com o tipo de ocorrencia selecionada, agrupando os resultados conforme os tipos de valores encontrados.
SELECT SEXO, COUNT(*) FROM CLIENTE GROUP BY SEXO; Nesse tipo de busca quando não definimos o GROUP BY temos como resultado a contagem de itens e o valor da primeira coluna do seletor pois o retorno do COUNT() é apenas uma linha.
Quando criamos querys com operadores lógicos, devemos pensar em como otimizar seus resultados. Quando fazemos uma seleção utilizando o OR devemos selecionar como primeira condição a que tem mais resultados, pois o operador é inclusivo. Dessa forma primeiro retornamos todos os valores compatíveis com a primeira regra (que são a maioria) para depois incluir as excessões (regra com menos valores). O contrário deve ser feito em operações com o AND. Por ser mais restritivo iniciamos a consulta sempre pelo valor com menos ocorrencias.
Seção 6 - Exercícios de Fixação 02
Aula 31 a 33 - Exercícios - Criando Banco de Dados / Resolvendo as primeras questões / Concluindo o exercício
create database exercicio;
use exercicio;
create table funcionarios
(
idFuncionario integer,
nome varchar(100),
email varchar(200),
sexo varchar(10),
departamento varchar(100),
admissao varchar(10),
salario integer,
cargo varchar(100),
idRegiao int
);
use exercicio;
create table funcionarios
(
idFuncionario integer,
nome varchar(100),
email varchar(200),
sexo varchar(10),
departamento varchar(100),
admissao varchar(10),
salario integer,
cargo varchar(100),
idRegiao int
);
Proposta do exercício:
- Traga os funcionarios que trabalhem no departamento de filmes OU no departamento de roupas
- O gestor de marketing pediu a lista das funcionarias que trabalhem no departamento de filmes ou no departamento lar. Ele necessita enviar um email para as colaboradoras desses dois setores.
- Traga os funcionarios do sexo masculino ou os funcionarios que trabalhem no setor Jardim
Para a execução na prática, devemos fazer essas análises em horários de poucas requisições no banco ou em um banco fora de produção (backup).
/* Primeira query */
/*Verificar o valor mais relevante para definir a ordem do filtro */
SELECT COUNT(*), departamento FROM funcionarios GROUP BY departamento ORDER BY 1 DESC;
/* Filtro do item com mais ocorrencias para o com menos ocorrencias */
SELECT nome, departamento FROM funcionarios WHERE departamento='roupas' OR departamento='filmes';
SELECT * FROM funcionarios WHERE departamento='roupas' OR departamento='filmes';
/* Segunda query */
SELECT COUNT(*), sexo FROM funcionarios GROUP BY sexo;
SELECT COUNT(*), departamento FROM funcionarios GROUP BY departamento ORDER BY 1 DESC;
SELECT nome, departamento, email FROM funcionarios WHERE (departamento='lar' OR departamento='filmes') AND sexo='Feminino';
/* Resolução sugerida */
SELECT nome, departamento, email FROM funcionarios WHERE (departamento='lar' AND sexo='Feminino') OR (departamento='filmes' AND sexo='Feminino');
/* Terceira query */
SELECT nome, departamento, sexo FROM funcionarios WHERE sexo='Masculino' OR departamento='Jardim';
/*Verificar o valor mais relevante para definir a ordem do filtro */
SELECT COUNT(*), departamento FROM funcionarios GROUP BY departamento ORDER BY 1 DESC;
/* Filtro do item com mais ocorrencias para o com menos ocorrencias */
SELECT nome, departamento FROM funcionarios WHERE departamento='roupas' OR departamento='filmes';
SELECT * FROM funcionarios WHERE departamento='roupas' OR departamento='filmes';
/* Segunda query */
SELECT COUNT(*), sexo FROM funcionarios GROUP BY sexo;
SELECT COUNT(*), departamento FROM funcionarios GROUP BY departamento ORDER BY 1 DESC;
SELECT nome, departamento, email FROM funcionarios WHERE (departamento='lar' OR departamento='filmes') AND sexo='Feminino';
/* Resolução sugerida */
SELECT nome, departamento, email FROM funcionarios WHERE (departamento='lar' AND sexo='Feminino') OR (departamento='filmes' AND sexo='Feminino');
/* Terceira query */
SELECT nome, departamento, sexo FROM funcionarios WHERE sexo='Masculino' OR departamento='Jardim';
Seção 7 - Mais alguns comandos básicos
Aula 34 a 36 - Filtrando valores nulos / A Cláusula UPDATE / A Cláusula DELETENesse caso utilizamos a expressão IS NULL ou seu inverso IS NOT NULL.
SELECT * FROM CLIENTE WHERE email IS NULL; Para atualizarmos dados em registros utlizamos o comando UPDATE tabela SET campo. O comando UPDATE deve sempre ser utilizado em conjunto com o comando WHERE para filtrar as ocorrencias em que se deseja a alteração, caso contrário podemos alterar todos os registros.
O comando WHERE é um dos mais importantes dos scripts SQL.
UPDATE CLIENTE SET EMAIL = '[email protected]' WHERE NOME = 'JOAO'; Quando perdemos os dados de um BD devido a um erro no comando UPDATE podemos retornar os valores originais com os comandos COMMIT e ROLLBACK (a serem estudados) ou restaurando um backup (mais problemático).
O comando DELETE pode apagar todos os registros de um BD.
Uma forma de fazer as exclusões com segurança é sempre realizar as contagens do BD antes e após a exclusão.
SELECT COUNT(*) FROM CLIENTE; -- Total 6
SELECT COUNT(*) FROM CLIENTE WHERE NOME='ANA'; --Total 1
DELETE FROM CLIENTE WHERE NOME='ANA';
SELECT COUNT(*) FROM CLIENTE; --Total 5
Podemos mesclar cláusulas de filtro com operadores
lógicos para refinar a exclusão: SELECT COUNT(*) FROM CLIENTE WHERE NOME='ANA'; --Total 1
DELETE FROM CLIENTE WHERE NOME='ANA';
SELECT COUNT(*) FROM CLIENTE; --Total 5
SELECT * FROM CLIENTE WHERE NOME='CARLA' AND
EMAIL = '[email protected]';
DELETE FROM CLIENTE WHERE NOME='CARLA' AND EMAIL = '[email protected]';
DELETE FROM CLIENTE WHERE NOME='CARLA' AND EMAIL = '[email protected]';
Seção 8 - Modelando Banco de Dados para Sistemas
Aula 37 a 39 - Começando a Modelar / A História da Modelagem / Primeira Forma NormalCom a evolução dos sistemas de informação foi desenvolvido um modelo onde se determinou que os procedimentos variam, apenas os dados são imutáveis. Esse modelo é chamado de MER. Para garantir uma consistencia na modelagem de dados foram criadas as formas normais. Existem em certas literaturas até 5 formas normais, mas entendendo a Primeira, Segunda e Terceira já conseguimos garantir a consistencia da modelagem de dados.
A Primeira Forma Normal possui tres regras:
1 - Todo campo vetorizado se tornará outra tabela: ou seja se um campo tem mais que um dado da mesma família ele deve gerar uma nova tabela de dados.
2 - Todo campo multivalorado se tornará outra tabela: ou seja quando o campo for divisível em valores diferentes ele deve gerar uma nova tabela(s).
3 - Toda tabela necessita de pelo menos um campo que identifique todo o registro como sendo único: é o que chamamos de Chave Primária ou Primary Key.
Nesse caso podemos pensar por exemplo no CPF como uma chave primária, pois é uma numeração única para cada indivíduo. Entretanto segundo a teoria do MER a chave não deve ser baseado a procedimento. O CPF é uma chave primária da Receita Federal. Por exemplo, caso o governo decida alterar o numero do CPF perdemos nossa chave, e consequentemente nosso modelo.
Existem dois tipos de chaves: a chave natural e a chave artificial. A chave natural de um indivíduo pode ser o CPF, pois ele é único para cada pessoa. Já uma chave artificial é criada em nosso banco de dados como um id. Muito embora a utilização de chaves naturais facilitem a interpretação dos dados as chaves artificiais são melhores quando pensamos em crescimento do BD.
Analisando o nosso BD CLIENTE podemos definir que temos uma tabela CLIENTE, uma tabela TELEFONE (regra 1 campo vetorizado pois uma pessoa pode ter mais que um telefone) e ENDERECO (regra 2 campo multivalorado pois o endereço é composto de rua, bairro, cidade, estado, etc.).
Aula 40 - Cardinalidade e Obrigatoriedade
Quando criamos relacionamentos entre tabelas usamos o
termo possui, portanto uma pessoa
possui um endereço, ou possui um telefone.
Todo relacionamento entre tabelas tem duas propriedades: cardinalidade e obigatoriedade. Essas propriedades são expressas na modelagem pela notação (0,n) onde o primeiro valor faz referencia a obrigatoriedade e o segundo a cardinalidade. Quem define a cardinalidade é a regra do negócio e nunca o AD ou DBA.
Quando observamos a regra de negócio acima deduzimos que:
O campo de endereço é obrigatório e só permite '1' inclusão;
O campo de telefone não é obrigatório e permite 'n' inclusões.
Na representação da obrigatoriedade temos os valores '0' não obrigatório e '1' obrigatório.
Na representação da cardinalidade temos os valores '1' apenas uma ocorrencia ou 'n' várias ocorrencias.
Desse modo temos para o endereço a representação (1,1) (1 - campo obrigatório, 1 - apenas uma inserção);
Para o telefone a representação é (0,n) (0 - campo não obrigatório, n - multiplas inserções).
Devemos observar esses critérios de acordo com quem está na ponta da relação:
O cliente deve ter endereço e só um. Cada endereço deve ter cliente e só pode ter um cliente (na verdade 1 endereço pode ter mais de 1 cliente entretanto no relacionamento o endereço é único, devendo ser um novo registro para um novo cliente no mesmo endereço). O cliente pode ter telefone e n numeros diferentes. Um telefone deve ter cliente e 1 apenas.
Por fim a relação de cardinalidade é feita utilizando o numero de cardinalidade de cada cruzamento, dessa forma cliente x telefone é 1 x n e cliente endereço é 1 x 1.
Todo relacionamento entre tabelas tem duas propriedades: cardinalidade e obigatoriedade. Essas propriedades são expressas na modelagem pela notação (0,n) onde o primeiro valor faz referencia a obrigatoriedade e o segundo a cardinalidade. Quem define a cardinalidade é a regra do negócio e nunca o AD ou DBA.
Estamos no início da modelagem para um sistema, e o
nosso gestor nos pediu a modelagem da tabela de
clientes com a seguinte regra de negócios:
ENDERECO - OBRIGATORIO O CADASTRO DE UM ENDERECO (NO MAXIMO 1)
TELEFONE - O CLIENTE NAO É OBRIGADO A INFORMAR TELEFONE POREM, CASO QUEIRA, ELE PODE INFORMAR MAIS DE UM
ENDERECO - OBRIGATORIO O CADASTRO DE UM ENDERECO (NO MAXIMO 1)
TELEFONE - O CLIENTE NAO É OBRIGADO A INFORMAR TELEFONE POREM, CASO QUEIRA, ELE PODE INFORMAR MAIS DE UM
Quando observamos a regra de negócio acima deduzimos que:
O campo de endereço é obrigatório e só permite '1' inclusão;
O campo de telefone não é obrigatório e permite 'n' inclusões.
Na representação da obrigatoriedade temos os valores '0' não obrigatório e '1' obrigatório.
Na representação da cardinalidade temos os valores '1' apenas uma ocorrencia ou 'n' várias ocorrencias.
Desse modo temos para o endereço a representação (1,1) (1 - campo obrigatório, 1 - apenas uma inserção);
Para o telefone a representação é (0,n) (0 - campo não obrigatório, n - multiplas inserções).
Devemos observar esses critérios de acordo com quem está na ponta da relação:
O cliente deve ter endereço e só um. Cada endereço deve ter cliente e só pode ter um cliente (na verdade 1 endereço pode ter mais de 1 cliente entretanto no relacionamento o endereço é único, devendo ser um novo registro para um novo cliente no mesmo endereço). O cliente pode ter telefone e n numeros diferentes. Um telefone deve ter cliente e 1 apenas.
Por fim a relação de cardinalidade é feita utilizando o numero de cardinalidade de cada cruzamento, dessa forma cliente x telefone é 1 x n e cliente endereço é 1 x 1.
Aula 41 a 42 - Modelo Lógico para Físico - Parte 01 /
Modelo Físico - Parte 02
Com base no modelo criado anteriormente vamos iniciar a
criação do BD e das tabelas.
A primeira tabela a ser criada é a de cliente. Nesta tabela para o campo SEXO utilizaremos o tipo ENUM. Esse tipo de dado é exclusivo do MySQL e é utilizado para limitar as opções desse campo aos valores definidos (no caso 'M' ou 'F'). Nos SGBD como SQL Server e Oracle fazemos isso utilizando as CONSTRAINTS.
Os campos NOME e SEXO são NOT NULL e os campos EMAIL e CPF são UNIQUE.
Criamos também as tabelas ENDERECO e TELEFONE.
A primeira tabela a ser criada é a de cliente. Nesta tabela para o campo SEXO utilizaremos o tipo ENUM. Esse tipo de dado é exclusivo do MySQL e é utilizado para limitar as opções desse campo aos valores definidos (no caso 'M' ou 'F'). Nos SGBD como SQL Server e Oracle fazemos isso utilizando as CONSTRAINTS.
Os campos NOME e SEXO são NOT NULL e os campos EMAIL e CPF são UNIQUE.
CREATE DATABASE cursoSQLAula41;
SHOW DATABASES;
USE cursoSQLAula41;
CREATE TABLE CLIENTE (
IDCLIENTE INT PRIMARY KEY AUTO_INCREMENT,
SEXO ENUM('M', 'F') NOT NULL,
NOME VARCHAR(30) NOT NULL,
EMAIL VARCHAR(30) UNIQUE,
CPF VARCHAR(15) UNIQUE
);
Nessas tabelas começãmos a trabalhar com o campo de
ID e a PRIMARY KEY ou chave primária da
tabela. Além disso utilizamos o
AUTO_INCREMENT para inserir valores
automaticamente aos campos de ID. SHOW DATABASES;
USE cursoSQLAula41;
CREATE TABLE CLIENTE (
IDCLIENTE INT PRIMARY KEY AUTO_INCREMENT,
SEXO ENUM('M', 'F') NOT NULL,
NOME VARCHAR(30) NOT NULL,
EMAIL VARCHAR(30) UNIQUE,
CPF VARCHAR(15) UNIQUE
);
Criamos também as tabelas ENDERECO e TELEFONE.
CREATE TABLE ENDERECO (
IDENDERECO INT PRIMARY KEY AUTO_INCREMENT,
RUA VARCHAR(30) NOT NULL,
BAIRRO VARCHAR(30) NOT NULL,
CIDADE VARCHAR(30) NOT NULL,
ESTADO CHAR(2) NOT NULL
);
CREATE TABLE TELEFONE (
IDTELEFONE INT PRIMARY KEY AUTO_INCREMENT,
TIPO ENUM('COML', 'RES', 'CEL') NOT NULL,
NUMERO VARCHAR(10) NOT NULL
);
IDENDERECO INT PRIMARY KEY AUTO_INCREMENT,
RUA VARCHAR(30) NOT NULL,
BAIRRO VARCHAR(30) NOT NULL,
CIDADE VARCHAR(30) NOT NULL,
ESTADO CHAR(2) NOT NULL
);
CREATE TABLE TELEFONE (
IDTELEFONE INT PRIMARY KEY AUTO_INCREMENT,
TIPO ENUM('COML', 'RES', 'CEL') NOT NULL,
NUMERO VARCHAR(10) NOT NULL
);
Aula 43 a 44 - Entendendo a Foreign Key - Parte 01 /
Foreign Key - Parte 02
Chave estrangeira é a chave primária de uma tabela que
vai até a outra tabela para fazer referencia entre
registros.
Dadas as tabelas abaixo:
Conforme nossa modelagem, sabemos que o relacionamento entre CLIENTE e TELEFONE é de (1 x N) e de CLIENTE e ENDERECO é de (1 x 1). Com essa definição podemos aplicar as seguintes regras:
Em relacionamentos 1 x 1 a chave sempre fica na tabela mais fraca. Para saber qual a tabela mais fraca devemos observar a regra de negócio. Nesse caso a tabela mais forte é o CLIENTE. Em um estacionamento por exemplo a tabela mais forte é CARRO e a mais fraca CLIENTE. Desse modo apenas com a análise podemos definir qual a tabela mais forte.
Em relacionamentos 1 x n a chave sempre ficará na cardinalidade 'n'. No nosso caso a cardinalidade 'n' está na tabela TELEFONE. Para justificar essa regra podemos analisar da seguinte forma. Se cada CLIENTE pode ter 'n' telefones ao acrescentar mais de uma chave de telefone no cliente teremos um vetor de chaves, logo segundo a primeira regra da Primeira Forma Normal se existe um vetor existe uma nova tabela.
A definição do nome das chaves (primária ou estrangeira) deve sempre manter um padrão em toda a modelagem. Dessa forma quando trabalhamos com um BD existente devemos seguir a padronização estabelecida. Para novos BDs podemos criar padrões como quisermos. No exemplo foram definidas as chaves primárias como 'IDnometabela' e as estrangeiras como 'ID_nomechaveestrangeira'. Desse modo o padrão para chaves estrangeiras é incluir o caractere '_' na chave quando ela é importada. Esse tipo de procedimento facilita a analise nos dicionários do BD.
Para apagar tabelas utilizamos o comando DROP TABLE nome_da_tabela.
Quando vamos criar as Foreign Key devemos adicionar as colunas nas tabelas definidas para receber o relacionamento. A coluna criada deve observar o mesmo tipo da chave importada.
Criada a coluna da Foreign Key fazemos o relacionamento:
FOREIGN KEY(nome_chave_estrangeira) REFERENCES tabela(nome_chave_importada)
Ainda com relação a cardinalidade quando temos um relacionamento 1 x 1 devemos definir a chave estrangeira como UNIQUE. Desse modo não podemos repetir a chave estrangeira o que garante que cada campo da tabela de origem só vai ter uma ocorrencia na tabela destino.
Apesar de não ter sido falado na aula, entendo que a Foreign Key do campo ENDERECO deve ser NOT NULL pois a regra de obrigatoriedade é '1'
Dadas as tabelas abaixo:
| ID | NOME |
|---|---|
| 1 | MAFRA |
| 2 | CLARA |
| 3 | JOAO |
| ID | BAIRRO | FKEND |
|---|---|---|
| 10 | CENTRO | 3 |
| 11 | LAPA | 1 |
| 12 | COPACABANA | 2 |
| ID | NUMERO | FKTEL |
|---|---|---|
| 25 | 564564 | 2 |
| 27 | 98451784 | 3 |
| 29 | 945848741 | 2 |
| 33 | 74584115 | 2 |
| 37 | 2548525485 | 3 |
Conforme nossa modelagem, sabemos que o relacionamento entre CLIENTE e TELEFONE é de (1 x N) e de CLIENTE e ENDERECO é de (1 x 1). Com essa definição podemos aplicar as seguintes regras:
Em relacionamentos 1 x 1 a chave sempre fica na tabela mais fraca. Para saber qual a tabela mais fraca devemos observar a regra de negócio. Nesse caso a tabela mais forte é o CLIENTE. Em um estacionamento por exemplo a tabela mais forte é CARRO e a mais fraca CLIENTE. Desse modo apenas com a análise podemos definir qual a tabela mais forte.
Em relacionamentos 1 x n a chave sempre ficará na cardinalidade 'n'. No nosso caso a cardinalidade 'n' está na tabela TELEFONE. Para justificar essa regra podemos analisar da seguinte forma. Se cada CLIENTE pode ter 'n' telefones ao acrescentar mais de uma chave de telefone no cliente teremos um vetor de chaves, logo segundo a primeira regra da Primeira Forma Normal se existe um vetor existe uma nova tabela.
A definição do nome das chaves (primária ou estrangeira) deve sempre manter um padrão em toda a modelagem. Dessa forma quando trabalhamos com um BD existente devemos seguir a padronização estabelecida. Para novos BDs podemos criar padrões como quisermos. No exemplo foram definidas as chaves primárias como 'IDnometabela' e as estrangeiras como 'ID_nomechaveestrangeira'. Desse modo o padrão para chaves estrangeiras é incluir o caractere '_' na chave quando ela é importada. Esse tipo de procedimento facilita a analise nos dicionários do BD.
Para apagar tabelas utilizamos o comando DROP TABLE nome_da_tabela.
Quando vamos criar as Foreign Key devemos adicionar as colunas nas tabelas definidas para receber o relacionamento. A coluna criada deve observar o mesmo tipo da chave importada.
Criada a coluna da Foreign Key fazemos o relacionamento:
FOREIGN KEY(nome_chave_estrangeira) REFERENCES tabela(nome_chave_importada)
Ainda com relação a cardinalidade quando temos um relacionamento 1 x 1 devemos definir a chave estrangeira como UNIQUE. Desse modo não podemos repetir a chave estrangeira o que garante que cada campo da tabela de origem só vai ter uma ocorrencia na tabela destino.
CREATE TABLE ENDERECO (
IDENDERECO INT PRIMARY KEY AUTO_INCREMENT,
RUA VARCHAR(30) NOT NULL,
BAIRRO VARCHAR(30) NOT NULL,
CIDADE VARCHAR(30) NOT NULL,
ESTADO CHAR(2) NOT NULL,
ID_CLIENTE INT UNIQUE,
FOREIGN KEY(ID_CLIENTE) REFERENCES CLIENTE(IDCLIENTE)
);
CREATE TABLE TELEFONE (
IDTELEFONE INT PRIMARY KEY AUTO_INCREMENT,
TIPO ENUM('COML', 'RES', 'CEL') NOT NULL,
NUMERO VARCHAR(10) NOT NULL,
ID_CLIENTE INT,
FOREIGN KEY(ID_CLIENTE) REFERENCES CLIENTE(IDCLIENTE)
);
IDENDERECO INT PRIMARY KEY AUTO_INCREMENT,
RUA VARCHAR(30) NOT NULL,
BAIRRO VARCHAR(30) NOT NULL,
CIDADE VARCHAR(30) NOT NULL,
ESTADO CHAR(2) NOT NULL,
ID_CLIENTE INT UNIQUE,
FOREIGN KEY(ID_CLIENTE) REFERENCES CLIENTE(IDCLIENTE)
);
CREATE TABLE TELEFONE (
IDTELEFONE INT PRIMARY KEY AUTO_INCREMENT,
TIPO ENUM('COML', 'RES', 'CEL') NOT NULL,
NUMERO VARCHAR(10) NOT NULL,
ID_CLIENTE INT,
FOREIGN KEY(ID_CLIENTE) REFERENCES CLIENTE(IDCLIENTE)
);
Apesar de não ter sido falado na aula, entendo que a Foreign Key do campo ENDERECO deve ser NOT NULL pois a regra de obrigatoriedade é '1'
Aula 46 a 48- Inserção de dados / Inserções em
relacionamentos 1 x 1 / Inserções 1 x N
As inserções de dados manuais como são feitas nas aulas
são geralmente feitas pelos DBAs. Uma aplicação em
produção é composta de uma camada de visão (html), uma
camada lógica (php, c#, java, js) que faz o
processamento e a geração do código SQL e por fim temos
a camada do BD que recebe e armazena os dados. Desse
modo a inserção de valores de várias tabelas uma a uma
não é a prática. Existe a possibilidade de inclusão em
várias tabelas por funções diretamente no SQL.
Para a inserção de dados iniciamos com a tabela CLIENTE. Sempre que vamos inserir dados em uma tabela devemos verificar seus campos, ordem e tipos com DESC tabela. No caso do MySQL o campo AUTO_INCREMENT deve ser informado como NULL para que o gerenciamento da chave fique por conta do BD.
Quando não inserimos algum valor das colunas (e quando não definimos os campos que serão informados) recebemos uma mensagem de erro.
Os relacionametos obrigatórios entre tabelas não são verificados pelo BD. Esse relacionamento deve ser implementado na camada de aplicação. As regras no BD se limitam as tabelas e suas propriedades.
Quando fazemos inclusão de campos com relacionamento por chave estrangeira temos que fazer a referencia para um registro válido. Caso a FOREIGN KEY não seja localizada na tabela em que é feita a referencia recebemos um erro. Isso garante a integridade relacional. Esse registro não é incluido mas o numero do ID é incrementado pois sempre que o registro é incluido, é checada a integridade referencial e ele é removido por erro nesse processo é mantido o valor do incremento. Entretanto as chaves primárias não precisam ser iguais. Apenas a chave estrangeira que deve ter a referencia correta.
Na inserção de dados 1 x 1 incluimos a restrição UNIQUE na FOREIGN KEY. Sendo assim o campo não permite a inclusão de dois endereços para o mesmo ID.
Apesar de não podermos inserir dados duplicados não setamos o campo como NOT NULL. Com isso temos dois problemas. O primeiro é que o endereço é obrigatório (1 ,1) e nessse caso não está. O segundo é que a constraint UNIQUE não verifica a repetição de campos do tipo NULL
Já nas inserções da tabela TELEFONE como temos um relacionamento tipo 1 x N podemos repetir a FOREIGN KEY quantas vezes for necessário.
Para a inserção de dados iniciamos com a tabela CLIENTE. Sempre que vamos inserir dados em uma tabela devemos verificar seus campos, ordem e tipos com DESC tabela. No caso do MySQL o campo AUTO_INCREMENT deve ser informado como NULL para que o gerenciamento da chave fique por conta do BD.
Quando não inserimos algum valor das colunas (e quando não definimos os campos que serão informados) recebemos uma mensagem de erro.
Os relacionametos obrigatórios entre tabelas não são verificados pelo BD. Esse relacionamento deve ser implementado na camada de aplicação. As regras no BD se limitam as tabelas e suas propriedades.
Quando fazemos inclusão de campos com relacionamento por chave estrangeira temos que fazer a referencia para um registro válido. Caso a FOREIGN KEY não seja localizada na tabela em que é feita a referencia recebemos um erro. Isso garante a integridade relacional. Esse registro não é incluido mas o numero do ID é incrementado pois sempre que o registro é incluido, é checada a integridade referencial e ele é removido por erro nesse processo é mantido o valor do incremento. Entretanto as chaves primárias não precisam ser iguais. Apenas a chave estrangeira que deve ter a referencia correta.
Na inserção de dados 1 x 1 incluimos a restrição UNIQUE na FOREIGN KEY. Sendo assim o campo não permite a inclusão de dois endereços para o mesmo ID.
Apesar de não podermos inserir dados duplicados não setamos o campo como NOT NULL. Com isso temos dois problemas. O primeiro é que o endereço é obrigatório (1 ,1) e nessse caso não está. O segundo é que a constraint UNIQUE não verifica a repetição de campos do tipo NULL
Já nas inserções da tabela TELEFONE como temos um relacionamento tipo 1 x N podemos repetir a FOREIGN KEY quantas vezes for necessário.
Seção 9 - Juntando as peças
Aula 49 a 51 - Seleção e projeção / Junção / Inner JoinProjeção: É tudo que voce quer ver na tela. Pode ser registros de tabela, o retorno de uma função (p.ex. SELECT NOW()) ou mesmo o retorno de uma operação matemática ou texto puro. A cláusula de projeção é o SELECT
SELECT 2 + 2 AS SOMA, NOME, NOW() FROM CLIENTE;
Acima temos o retorno de uma soma, o NOME da tabela CLIENTE e a Hora e Data atual.
Podemos sempre iniciar a construção de uma query pela projeção, mesmo que não saibamos ainda de onde virão os dados, isto é, a projeção é a sintese do que é solicitado e através dela iniciamos a construção da query.
Banco de dados tem por premissa teoria de conjuntos.
Seleção: É um sub-conjunto de dados partindo conjunto total de uma tabela. A cláusula de seleção é o WHERE.
É possível fazer junção com o WHERE entretanto essa não é a cláusula apropriada.
SELECT NOME, SEXO, EMAIL /* Projeção */
FROM CLIENTE /* Origem */
WHERE SEXO = 'F' /* Seleção */
A Junção é a combinação de duas ou mais tabelas
através de um elemento comum (chave primária / chave
estrangeira). FROM CLIENTE /* Origem */
WHERE SEXO = 'F' /* Seleção */
Como dito anteriormente podemos fazer uma junção através da cláusula de seleção:
SELECT NOME, SEXO, BAIRRO, CIDADE
FROM CLIENTE, ENDERECO
WHERE IDCLIENTE = ID_CLIENTE AND SEXO = 'F';
Note que na instrução acima selecionamos campos de
tabelas diferentes e fazemos a junção recuperando
através de um filtro de seleção os valores das tabelas
por comparação. O problema é que quando adicionamos mais
seleções a query começamos a realizar comparações
lógicas (tabela verdade) desnecessárias pois sempre o
valor das chaves serão iguais. Isso portanto diminui a
performance do BD. Como dito anteriormente a regra que
cria a FOREIGN KEY garante que haja uma
integridade referencial no BD, ou seja a
igualdade das chaves é sempre verdadeiro.FROM CLIENTE, ENDERECO
WHERE IDCLIENTE = ID_CLIENTE AND SEXO = 'F';
A cláusula de junção é o INNER JOIN...ON (juntar internamente). Desse modo fazemos a ligação das chaves entre as tabelas sem a necessidade de fazer a seleção, apenas pela comparação referencial.
SELECT NOME, SEXO, BAIRRO, CIDADE
FROM CLIENTE
INNER JOIN ENDERECO
ON IDCLIENTE=ID_CLIENTE
WHERE SEXO='F';
Nos relacionamentos 1 x N não há como evitar a
repetição dos valores com menos registros. Isso só é
possível com relatórios. FROM CLIENTE
INNER JOIN ENDERECO
ON IDCLIENTE=ID_CLIENTE
WHERE SEXO='F';
Para fazer a junção de várias tabelas somente é necessário realizar novos INNER JOIN. Entretanto quando temos nomes iguais de chaves em tabelas diferentes a junção retorna um erro de ambiguidade. Para resolver isso devemos apontar os atributos para suas respectivas tabelas.
Na minha solução apontei apenas os valores com nomes iguais, entretanto o apontamento do professor foi para todos os campos da query:
SELECT CLIENTE.NOME, CLIENTE.SEXO,
ENDERECO.BAIRRO, ENDERECO.CIDADE, TELEFONE.TIPO,
TELEFONE.NUMERO
FROM CLIENTE
INNER JOIN ENDERECO
ON CLIENTE.IDCLIENTE = ENDERECO.ID_CLIENTE
INNER JOIN TELEFONE
ON CLIENTE.IDCLIENTE = TELEFONE.ID_CLIENTE;
Podemos ainda utilizar apelidos para as tabelas o que
melhora a performance geral da query. Além disso os
apontamentos melhoram a performance do BD uma vez que a
query já busca os campos diretamente pelo apontamento e
não precisa ficar processando a qual tabela esse campo
pertence. FROM CLIENTE
INNER JOIN ENDERECO
ON CLIENTE.IDCLIENTE = ENDERECO.ID_CLIENTE
INNER JOIN TELEFONE
ON CLIENTE.IDCLIENTE = TELEFONE.ID_CLIENTE;
SELECT C.NOME, C.SEXO, E.BAIRRO, E.CIDADE,
T.TIPO, T.NUMERO
FROM CLIENTE AS C
INNER JOIN ENDERECO AS E
ON C.IDCLIENTE = E.ID_CLIENTE
INNER JOIN TELEFONE AS T
ON C.IDCLIENTE = T.ID_CLIENTE;
FROM CLIENTE AS C
INNER JOIN ENDERECO AS E
ON C.IDCLIENTE = E.ID_CLIENTE
INNER JOIN TELEFONE AS T
ON C.IDCLIENTE = T.ID_CLIENTE;
Aula 52 a 53 - Comandos de DML / DDL - Modificando
tabelas
Categorias de comandos em BD. O SQL é uma linguagem de
programamção de quarta geração, ou seja parecida com a
linguagem natural. As categorias em SQL são:
DML: Data Manipulation Language (manipulação de dados).
DDL: Data Definition Language (definição e tipagem dos dados).
DCL: Data Control Language (controle de acesso e usuários).
TCL: Transaction Control Language (controle de transação).
Cláusulas de DML:
INSERT: inserção de dados;
SELECT: projeção de dados;
WHERE: filtro de seleção;
UPDATE: atualiza dados da tabela.
DELETE: remove dados da tabela.
Quando definimos na regra de negócio e consequentemente na cardinalidade uma relação de 1 x 1 teremos registros repetidos em casos de dados homonimos. A regra 1 x 1 exige 1 registro para cada elemento dessa forma caso duas pessoas morem em um mesmo endereço e a regra de relacionamento entre cliente e endereço seja 1 x 1 teremos dois registros de endereço iguais em chaves diferentes.
Cláusulas de DDL:
Alteram a estrutura da tabela.
CREATE: cria uma tabela com as propriedades definidas;
ALTER TABLE: responsável pela alteração de tabelas;
CHANGE: faz alterações na tabela mas exige a declaração da coluna de origem e de destino (mesmo que a alteração não seja no nome da coluna).
MODIFY: o mesmo que a cláusula CHANGE porém permite fazer a alteração de tipo e outras propriedades sem declarar o nome da coluna duas vezes.
ADD COLUMN: adiciona uma coluna;
AFTER: adiciona a coluna depois de uma coluna específica; FIRST: adiciona a coluna na primeira posição da tabela;
DROP COLUMN: remove uma coluna;
DML: Data Manipulation Language (manipulação de dados).
DDL: Data Definition Language (definição e tipagem dos dados).
DCL: Data Control Language (controle de acesso e usuários).
TCL: Transaction Control Language (controle de transação).
Cláusulas de DML:
INSERT: inserção de dados;
SELECT: projeção de dados;
WHERE: filtro de seleção;
UPDATE: atualiza dados da tabela.
DELETE: remove dados da tabela.
Quando definimos na regra de negócio e consequentemente na cardinalidade uma relação de 1 x 1 teremos registros repetidos em casos de dados homonimos. A regra 1 x 1 exige 1 registro para cada elemento dessa forma caso duas pessoas morem em um mesmo endereço e a regra de relacionamento entre cliente e endereço seja 1 x 1 teremos dois registros de endereço iguais em chaves diferentes.
INSERT INTO CLIENTE VALUES (NULL, 'PAULA', 'M',
NULL, '77437493');
INSERT INTO ENDERECO VALUES (NULL, 'RUA JOAQUIM SILVA', 'ALVORADA', 'NITEROI', 'RJ', 7);
SELECT * FROM CLIENTE WHERE SEXO='M';
UPDATE CLIENTE SET SEXO='F' WHERE IDCLIENTE=7;
INSERT INTO CLIENTE VALUES (NULL, 'XXX', 'M', NULL, 'XXX');
DELETE FROM CLIENTE WHERE IDCLIENTE=8;
INSERT INTO ENDERECO VALUES (NULL, 'RUA JOAQUIM SILVA', 'ALVORADA', 'NITEROI', 'RJ', 7);
SELECT * FROM CLIENTE WHERE SEXO='M';
UPDATE CLIENTE SET SEXO='F' WHERE IDCLIENTE=7;
INSERT INTO CLIENTE VALUES (NULL, 'XXX', 'M', NULL, 'XXX');
DELETE FROM CLIENTE WHERE IDCLIENTE=8;
Cláusulas de DDL:
Alteram a estrutura da tabela.
CREATE: cria uma tabela com as propriedades definidas;
ALTER TABLE: responsável pela alteração de tabelas;
CHANGE: faz alterações na tabela mas exige a declaração da coluna de origem e de destino (mesmo que a alteração não seja no nome da coluna).
MODIFY: o mesmo que a cláusula CHANGE porém permite fazer a alteração de tipo e outras propriedades sem declarar o nome da coluna duas vezes.
ADD COLUMN: adiciona uma coluna;
AFTER: adiciona a coluna depois de uma coluna específica; FIRST: adiciona a coluna na primeira posição da tabela;
DROP COLUMN: remove uma coluna;
CREATE TABLE PRODUTO(
IDPRODUTO INT PRIMARY KEY AUTO_INCREMENT,
NOME_PRODUTO VARCHAR(30) NOT NULL,
PRECO INT,
FRETE FLOAT(10,2) NOT NULL
);
ALTER TABLE PRODUTO
CHANGE PRECO VALOR_UNITARIO INT NOT NULL;
ALTER TABLE PRODUTO
CHANGE VALOR_UNITARIO VALOR_UNITARIO INT;
ALTER TABLE PRODUTO
MODIFY VALOR_UNITARIO VARCHAR(50) NOT NULL;
ALTER TABLE PRODUTO
ADD COLUMN PESO FLOAT(10,2) NOT NULL;
ALTER TABLE PRODUTO
DROP COLUMN PESO;
ALTER TABLE PRODUTO
ADD COLUMN PESO FLOAT(10,2) NOT NULL
AFTER NOME_PRODUTO;
ALTER TABLE PRODUTO
DROP COLUMN PESO;
ALTER TABLE PRODUTO
ADD COLUMN PESO FLOAT(10,2) NOT NULL
FIRST;
IDPRODUTO INT PRIMARY KEY AUTO_INCREMENT,
NOME_PRODUTO VARCHAR(30) NOT NULL,
PRECO INT,
FRETE FLOAT(10,2) NOT NULL
);
ALTER TABLE PRODUTO
CHANGE PRECO VALOR_UNITARIO INT NOT NULL;
ALTER TABLE PRODUTO
CHANGE VALOR_UNITARIO VALOR_UNITARIO INT;
ALTER TABLE PRODUTO
MODIFY VALOR_UNITARIO VARCHAR(50) NOT NULL;
ALTER TABLE PRODUTO
ADD COLUMN PESO FLOAT(10,2) NOT NULL;
ALTER TABLE PRODUTO
DROP COLUMN PESO;
ALTER TABLE PRODUTO
ADD COLUMN PESO FLOAT(10,2) NOT NULL
AFTER NOME_PRODUTO;
ALTER TABLE PRODUTO
DROP COLUMN PESO;
ALTER TABLE PRODUTO
ADD COLUMN PESO FLOAT(10,2) NOT NULL
FIRST;
Seção 10 - Exercícios de Fixação 03
Aula 54 a 56 - Exercícios de Fixação - 03 / Correção DML - Parte 01 / Correção DML - Parte 02- RELATORIO GERAL DE TODOS OS CLIENTES
- RELATORIO DE HOMENS
- RELATORIO DE MULHERES
- QUANTIDADE DE HOMENS E MULHERES
- IDS E EMAIL DAS MULHERES QUE MOREM NO CENTRO DO RIO DE JANEIRO E NÃO TENHAM CELULAR
SELECT NOME, SEXO, EMAIL, CPF FROM CLIENTE;
SELECT NOME, SEXO, EMAIL, CPF
FROM CLIENTE
WHERE SEXO='M';
SELECT NOME, SEXO, EMAIL, CPF
FROM CLIENTE
WHERE SEXO='F';
SELECT SEXO, COUNT(*) FROM CLIENTE GROUP BY SEXO;
SELECT C.IDCLIENTE, C.EMAIL FROM CLIENTE C
INNER JOIN ENDERECO E
ON C.IDCLIENTE = E.ID_CLIENTE
LEFT JOIN TELEFONE T
ON C.IDCLIENTE = T.ID_CLIENTE
WHERE T.TIPO IS NULL AND (E.BAIRRO='CENTRO' AND E.CIDADE='RIO DE JANEIRO') AND C.SEXO='F';
Para a solução do exercício foi feito em primeiro lugar
a listagem completa com todos os dados (inclusive
endereço e telefone).
SELECT NOME, SEXO, EMAIL, CPF
FROM CLIENTE
WHERE SEXO='M';
SELECT NOME, SEXO, EMAIL, CPF
FROM CLIENTE
WHERE SEXO='F';
SELECT SEXO, COUNT(*) FROM CLIENTE GROUP BY SEXO;
SELECT C.IDCLIENTE, C.EMAIL FROM CLIENTE C
INNER JOIN ENDERECO E
ON C.IDCLIENTE = E.ID_CLIENTE
LEFT JOIN TELEFONE T
ON C.IDCLIENTE = T.ID_CLIENTE
WHERE T.TIPO IS NULL AND (E.BAIRRO='CENTRO' AND E.CIDADE='RIO DE JANEIRO') AND C.SEXO='F';
SELECT C.IDCLIENTE, C.NOME, C.SEXO, C.EMAIL,
C.CPF, E.RUA, E.BAIRRO, E.CIDADE, E.ESTADO,
T.TIPO, T.NUMERO
FROM CLIENTE AS C
INNER JOIN ENDERECO AS E
ON C.IDCLIENTE = E.ID_CLIENTE
LEFT JOIN TELEFONE AS T
ON C.IDCLIENTE = T.ID_CLIENTE;
Em seguida nas relações por sexo foram feitos os ajustes
dos dados incorretos. FROM CLIENTE AS C
INNER JOIN ENDERECO AS E
ON C.IDCLIENTE = E.ID_CLIENTE
LEFT JOIN TELEFONE AS T
ON C.IDCLIENTE = T.ID_CLIENTE;
Na analise da ultima proposta fiz a solução para quem não tinha nenhum tipo de telefone (aqui fiquei bastante tempo para descobrir como utilizar o LEFT JOIN) mas na verdade a pesquisa é para quem não tem "CELULAR". Assim a resposta ficou da seguinte forma:
SELECT C.IDCLIENTE, C.EMAIL, C.NOME FROM CLIENTE
C
INNER JOIN ENDERECO E
ON C.IDCLIENTE = E.ID_CLIENTE
LEFT JOIN TELEFONE T
ON C.IDCLIENTE = T.ID_CLIENTE
WHERE T.TIPO!='CEL' AND (E.BAIRRO='CENTRO' AND E.CIDADE='RIO DE JANEIRO') AND C.SEXO='F';
O professor não utilizou o '!' mas sim
(T.TIPO = 'RES' OR T.TIPO = 'COM'). INNER JOIN ENDERECO E
ON C.IDCLIENTE = E.ID_CLIENTE
LEFT JOIN TELEFONE T
ON C.IDCLIENTE = T.ID_CLIENTE
WHERE T.TIPO!='CEL' AND (E.BAIRRO='CENTRO' AND E.CIDADE='RIO DE JANEIRO') AND C.SEXO='F';
Foram propostas mais duas querys:
- PARA UMA CAMPANHA DE MARKETING, O SETOR SOLICITOU UM RELATÓRIO COM O NOME, EMAIL E TELEFONE CELULAR DOS CLIENTES QUE MORAM NO ESTADO DO RIO DE JANEIRO VOCÊ TERÁ QUE PASSAR A QUERY PARA GERAR O RELATORIO PARA O PROGRAMADOR
- PARA UMA CAMPANHA DE PRODUTOS DE BELEZA, O COMERCIAL SOLICITOU UM RELATÓRIO COM O NOME, EMAIL E TELEFONE CELULAR DAS MULHERES QUE MORAM NO ESTADO DE SÃO PAULO VOCÊ TERÁ QUE PASSAR A QUERY PARA GERAR O RELATORIO PARA O PROGRAMADOR
SELECT C.IDCLIENTE, C.NOME, C.EMAIL, T.NUMERO
AS CELULAR
FROM CLIENTE AS C
INNER JOIN ENDERECO AS E
ON C.IDCLIENTE = E.ID_CLIENTE
LEFT JOIN TELEFONE AS T
ON C.IDCLIENTE = T.ID_CLIENTE
WHERE T.TIPO='CEL' AND E.ESTADO = 'RJ';
SELECT C.IDCLIENTE, C.NOME, C.EMAIL, T.TIPO,T.NUMERO AS CELULAR
FROM CLIENTE AS C
INNER JOIN ENDERECO AS E
ON C.IDCLIENTE = E.ID_CLIENTE
LEFT JOIN TELEFONE AS T
ON C.IDCLIENTE = T.ID_CLIENTE
WHERE T.TIPO='CEL'
AND E.ESTADO = 'SP'
AND C.SEXO='F';
FROM CLIENTE AS C
INNER JOIN ENDERECO AS E
ON C.IDCLIENTE = E.ID_CLIENTE
LEFT JOIN TELEFONE AS T
ON C.IDCLIENTE = T.ID_CLIENTE
WHERE T.TIPO='CEL' AND E.ESTADO = 'RJ';
SELECT C.IDCLIENTE, C.NOME, C.EMAIL, T.TIPO,T.NUMERO AS CELULAR
FROM CLIENTE AS C
INNER JOIN ENDERECO AS E
ON C.IDCLIENTE = E.ID_CLIENTE
LEFT JOIN TELEFONE AS T
ON C.IDCLIENTE = T.ID_CLIENTE
WHERE T.TIPO='CEL'
AND E.ESTADO = 'SP'
AND C.SEXO='F';
Seção 11 - Aprofundando
Aula 57 a 60 - Funções IFNULL / Views / Operações de DML em Views / Ordenando DadosOutra função do SQL é a IFNULL(). Esta função recebe dois parametros: coluna, string onde coluna é a coluna que se deseja verificar e string é o valor a ser apresentado na coluna.
Essa função pode ser utilizada na projeção para substituir campos do tipo NULL por valores de melhor apresentação. Quando utilizamos essa função na projeção temos sua representação no cabeçalho, assim devemos substituir seu nome por um alias.
SELECT C.NOME, IFNULL(C.EMAIL, '-') AS EMAIL,
E.ESTADO, IFNULL(T.NUMERO, '-') AS NUMERO
FROM CLIENTE AS C
INNER JOIN ENDERECO AS E
ON C.IDCLIENTE = E.ID_CLIENTE
LEFT JOIN TELEFONE AS T
ON C.IDCLIENTE = T.ID_CLIENTE;
Quando temos querys que são utilizadas com frequencia
podemos criar VIEWs que armazenem essas querys
e que podem ser projetadas diretamente pelo seu nome.
FROM CLIENTE AS C
INNER JOIN ENDERECO AS E
ON C.IDCLIENTE = E.ID_CLIENTE
LEFT JOIN TELEFONE AS T
ON C.IDCLIENTE = T.ID_CLIENTE;
CREATE VIEW RELATORIO AS
SELECT C.IDCLIENTE, C.NOME, C.SEXO, C.EMAIL,
T.TIPO, T.NUMERO,
E.BAIRRO, E.CIDADE, E.ESTADO
FROM CLIENTE AS C
INNER JOIN ENDERECO AS E
ON C.IDCLIENTE = E.ID_CLIENTE
INNER JOIN TELEFONE AS T
ON C.IDCLIENTE = T.ID_CLIENTE;
SELECT * FROM RELATORIO;
SELECT C.IDCLIENTE, C.NOME, C.SEXO, C.EMAIL,
T.TIPO, T.NUMERO,
E.BAIRRO, E.CIDADE, E.ESTADO
FROM CLIENTE AS C
INNER JOIN ENDERECO AS E
ON C.IDCLIENTE = E.ID_CLIENTE
INNER JOIN TELEFONE AS T
ON C.IDCLIENTE = T.ID_CLIENTE;
SELECT * FROM RELATORIO;
Quando criamos uma VIEW ela fica representada como uma nova tabela no BD. Ela se apresenta como uma tabela virtual com todos os campos definidos e inclusive com a cláusula DESC.
Para apagar uma VIEW utilizamos o comando:
DROP VIEW nome_da_view
Para evitar que as views se misturem com as tabelas podemos definir padrões de nomes para facilitar a visualização (no exemplo utilizamos o prefixo 'V_'). Podemos criar projeções personalizadas através de uma VIEW como se estivessemos operando com uma tabela completa.
SELECT NOME, NUMERO, ESTADO FROM V_RELATORIO;
Podemos fazer algumas operações de DML em VIEW com algumas restrições:
Não é possível fazer operações de DELETE e INSERT em views que utilizam JOIN.
Podemos fazer operações de UPDATE em views com JOIN.
Em views de tabelas simples podemos fazer todas as operações entretanto devemos nos atentar as restrições de campos. Em views com menos campos que a tabela original são aceitos apenas os campos definidos na view, campos da tabela que não estejam na view não são aceitos. Os campos que sejam do tipo NOT NULL são preenchidos automaticamente.
As operações de seleção são permitidas em todos os casos.
A VIEW portanto é um ponteiro para a tabela, e todas as alterações feitas nela são replicadas na tabela original a que ela se refere.
A ordenação de tabelas é feita com o comando ORDER BY.
Podemos ordenar pelo nome da coluna, ou pelo numero da coluna na projeção.
Para definir a classificação utilizamos ASC (padrão ascendente) ou DESC (descendente).
Seção 13 - Programando em MySQL
Aula 62 - DelimiterAtravés do comando de infraestrutura STATUS podemos ver entre outras informações da aplicação o caractere atual do delimitador.
O delimitador é essencial para a criação de procedures.
Alteramos o delimitador com o comando DELIMITER. Devemos ter cautela ao fazer essa alteração pois até que ela seja setada novamente ou o banco seja reiniciado teremos a alteração de seu padrão. Não devemos utilizar espaços na criação de delimitadores pois podemos deixar o sistema confuso.
Aula 63 a 65 - Iniciando com Programação em Bancos de
Dados / Procedures no Mundo Real / Procedures coom Query
- Parametros
Stored Procedures são blocos de programação que
ficam armazenados no BD. Temos blocos de programação
anonimos quando executamos uma linha diretamente em
linha de comando e blocos nomeados que ficam armazenados
e podem ser executados a qualquer momento.
Uma PROCEDURE é criada com o comando:
Para executar uma PROCEDURE utilizamos o comando CALL.
Podemos criar PROCEDURES sem ou com parametros (mesmo comportamento das funções).
As desvantagens em ambos os casos são a dificuldade de portabilidade (tanto os bancos quanto as linguagens de programação utilizam sintaxes diferentes). Outra questão a se avaliar é qual das camadas exige maior processamento. Cada caso pode equilibrar as regras de acordo com suas especificidades.
Como vimos as PROCEDURES servem para programar funções de CONTOLLER diretamente no BD. Vamos em princípio criar PROCCEDURES para fazer a inclusão de dados e projeção de dados diretamente no BD, de modo a permitir passar diretamente da VIEW para o MODEL.
Quando criamos procedures é sempre bom mantermos padrões. No caso de parametros podemos iniciar os valores com a letra 'V_' (variável).
Para essa aula criamos a seguinte tabela e a procedure de inclusão de dados como a seguir:
Uma PROCEDURE é criada com o comando:
DELIMITER $
CREATE PROCEDURE nome_da_procedure()
BEGIN
corpo do programa;
END
$
A alteração do DELIMITER é necessária para que
a procedure não seja encerrada no meio de sua leitura. O
símbolo utilizado como DELIMITER não precisa se
o '$'. O ideal é sempre voltar com o
DELIMITER ao padrão após a Criação da
PROCEDURECREATE PROCEDURE nome_da_procedure()
BEGIN
corpo do programa;
END
$
Para executar uma PROCEDURE utilizamos o comando CALL.
Podemos criar PROCEDURES sem ou com parametros (mesmo comportamento das funções).
DELIMITER $
CREATE PROCEDURE CONTA(NUMERO1 INT, NUMERO2 INT)
BEGIN
SELECT NUMERO1 + NUMERO2 AS CONTA;
END
$
DELIMITER ;
CALL CONTA(100,50);
Considerando que aplicações são projetadas em
MVC temos a
camada de View que faz a interface com o usuário
e as camadas de Controler e Model. A
camada Model contém o banco de dados e a
Controller as instruções de comunicação entre a
View e o Model. As regras de negócio podem
ser tratadas tanto pelo Controller quanto pelo
Model. Aqui entram as Pocedures. Essas
abordagens tem prós e contras. Em ambos os casos teremos
uma maior carga na camada escolhida para o processamento
da regras. Entre as vantagens de utilizar
procedures está a proteção contra ataques do
tipo SQL Injection pois os parametros são
passados diretamente na procedure sem manipulação SQL.
CREATE PROCEDURE CONTA(NUMERO1 INT, NUMERO2 INT)
BEGIN
SELECT NUMERO1 + NUMERO2 AS CONTA;
END
$
DELIMITER ;
CALL CONTA(100,50);
As desvantagens em ambos os casos são a dificuldade de portabilidade (tanto os bancos quanto as linguagens de programação utilizam sintaxes diferentes). Outra questão a se avaliar é qual das camadas exige maior processamento. Cada caso pode equilibrar as regras de acordo com suas especificidades.
Como vimos as PROCEDURES servem para programar funções de CONTOLLER diretamente no BD. Vamos em princípio criar PROCCEDURES para fazer a inclusão de dados e projeção de dados diretamente no BD, de modo a permitir passar diretamente da VIEW para o MODEL.
Quando criamos procedures é sempre bom mantermos padrões. No caso de parametros podemos iniciar os valores com a letra 'V_' (variável).
Para essa aula criamos a seguinte tabela e a procedure de inclusão de dados como a seguir:
CREATE TABLE CURSOS(
IDCURSO INT PRIMARY KEY AUTO_INCREMENT,
NOME VARCHAR(30) NOT NULL,
HORAS INT(3) NOT NULL,
VALOR FLOAT(10,2) NOT NULL
);
DELIMITER #
CREATE PROCEDURE CAD_CURSO(V_NOME VARCHAR(30), V_HORAS INT(3), V_PRECO FLOAT(10,2))
BEGIN
INSERT INTO CURSOS VALUES(NULL, V_NOME, V_HORAS, V_PRECO);
END
#
DELIMITER ;
Em seguida criamos uma PROCEDURE para consulta
dos registros. Tentei fazer uma consulta com os
'%'(coringas) mas não sei como concatenar o caractere
com o nome da variável.
IDCURSO INT PRIMARY KEY AUTO_INCREMENT,
NOME VARCHAR(30) NOT NULL,
HORAS INT(3) NOT NULL,
VALOR FLOAT(10,2) NOT NULL
);
DELIMITER #
CREATE PROCEDURE CAD_CURSO(V_NOME VARCHAR(30), V_HORAS INT(3), V_PRECO FLOAT(10,2))
BEGIN
INSERT INTO CURSOS VALUES(NULL, V_NOME, V_HORAS, V_PRECO);
END
#
DELIMITER ;
Seção 14 - Agregue, some, me de a média e tudo mais - Funções de agregação
Aula 67 a 68 - Group By, Count, Max, Min, Avg e funções do MySQL / Tudo certo mais eu quero a soma - Utilizando o SUM!MIN(): retorna o valor menor em uma coluna;
AVG(): retorna o valor da média dos valores de uma coluna.
TRUNCATE(valor, casas_decimais): ajusta o numero de casas decimais de um valor.
SUM(): realiza a soma de valores em uma coluna.
Podemos projetar os valores de diversas agragações diferentes, bem como agrupar os valores de acordo com critérios com o GROUP BY.
SELECT MAX(JANEIRO) AS MAX_JAN,
MIN(JANEIRO) AS MIN_JAN,
TRUNCATE(AVG(JANEIRO),2) AS MEDIA_JAN
FROM VENDEDORES;
SELECT SUM(JANEIRO) AS TOTAL_JAN,
SUM(FEVEREIRO) AS TOTAL_FEV,
SUM(MARCO) AS TOTAL_MAR
FROM VENDEDORES;
SELECT SEXO, SUM(MARCO) AS TOTAL_MAR
FROM VENDEDORES
GROUP BY SEXO;
MIN(JANEIRO) AS MIN_JAN,
TRUNCATE(AVG(JANEIRO),2) AS MEDIA_JAN
FROM VENDEDORES;
SELECT SUM(JANEIRO) AS TOTAL_JAN,
SUM(FEVEREIRO) AS TOTAL_FEV,
SUM(MARCO) AS TOTAL_MAR
FROM VENDEDORES;
SELECT SEXO, SUM(MARCO) AS TOTAL_MAR
FROM VENDEDORES
GROUP BY SEXO;
Seção 15 - Subconjunto do Conjunto
Aula 69 A 70 - Utilizando Subqueries / Somei as colunas. Mas e as linhas? Operações aritméticas.O nome da querry interna é INNER QUERY e é executada antes da query principal. A query principal é chamada de OUTER QUERY.
SELECT NOME, MARCO AS VALOR_MAR FROM VENDEDORES
WHERE MARCO=(SELECT MIN(MARCO) FROM VENDEDORES);
SELECT NOME, MARCO AS VALOR_MAR FROM VENDEDORES
WHERE MARCO=(SELECT MAX(MARCO) FROM VENDEDORES);
SELECT NOME, MARCO AS VALOR_MAR FROM VENDEDORES
WHERE MARCO=(SELECT MIN(MARCO) FROM VENDEDORES) OR MARCO=(SELECT MAX(MARCO) FROM VENDEDORES);
SELECT NOME, FEVEREIRO AS VALOR_FEV FROM VENDEDORES
WHERE FEVEREIRO > (SELECT AVG(FEVEREIRO) FROM VENDEDORES);
Podemos fazer operações matemáticas com as linhas
selecionando quais as colunas farão parte da operação e
quais as operações desejadas. o resultado será em uma
projeção diretamente em uma nova coluna. WHERE MARCO=(SELECT MIN(MARCO) FROM VENDEDORES);
SELECT NOME, MARCO AS VALOR_MAR FROM VENDEDORES
WHERE MARCO=(SELECT MAX(MARCO) FROM VENDEDORES);
SELECT NOME, MARCO AS VALOR_MAR FROM VENDEDORES
WHERE MARCO=(SELECT MIN(MARCO) FROM VENDEDORES) OR MARCO=(SELECT MAX(MARCO) FROM VENDEDORES);
SELECT NOME, FEVEREIRO AS VALOR_FEV FROM VENDEDORES
WHERE FEVEREIRO > (SELECT AVG(FEVEREIRO) FROM VENDEDORES);
SELECT NOME, JANEIRO, FEVEREIRO, MARCO,
(JANEIRO + FEVEREIRO + MARCO) AS TOTAL,
(JANEIRO + FEVEREIRO + MARCO) * .25 AS DESCONTO,
TRUNCATE((JANEIRO + FEVEREIRO + MARCO)/3,2) AS MEDIA
FROM VENDEDORES;
(JANEIRO + FEVEREIRO + MARCO) AS TOTAL,
(JANEIRO + FEVEREIRO + MARCO) * .25 AS DESCONTO,
TRUNCATE((JANEIRO + FEVEREIRO + MARCO)/3,2) AS MEDIA
FROM VENDEDORES;
Seção 16 - Oraganizando a casa - O dicionário de dados
Aula 71 - Verificando e alterando a estrutura de uma tabela, seus objetos e charsetsPrimeiro fizemos a inclusão da PRIMARY KEY após a criação da tabela.
ALTER TABLE ADD PRIMARY KEY(COLUNA1);
O professor falou que não é possível incluir o AUTO_INCREMENT porém isso porque o campo está como VARCHAR. Se alterarmos para INT podemos alterar com o comando:
ALTER TABLE TABELA MODIFY COLUNA1 INT AUTO_INCREMENT;
Podemos fazer inclusão de colunas inclusive selecionando sua posição com o comando:
ALTER TABLE TABELA ADD COLUNA4 VARCHAR(30) NOT NULL UNIQUE AFTER COLUNA3;
Para fazer alterações nos tipos das colunas precisamos verificar primeiramente se existem dados e se o tipo de dados armazenado é compatível com o novo tipo.
ALTER TABLE TABELA MODIFY COLUNA2 DATE NOT NULL;
Para renomear uma tabela utilizamos o ALTER TABLE com o comando RENAME:
ALTER TABLE TABELA RENAME PESSOA;
Assim como podemos inserir uma PRIMARY KEY posteriormente também podemos inserir uma FOREIGN KEY:
ALTER TABLE TIME ADD FOREIGN KEY(ID_PESSOA) REFERENCES PESSOA(COLUNA1);
Além do comando DESC table para vermos a estrutura de uma tabela podemos utilizar o comando SHOW CREATE TABLE que faz um detalhamento maior sobre a tabela, incluindo ENGINE do BD e CHARSET padrão.
SHOW CREATE TABLE TIME;
Aula 72 a 74 - Organizando as chaves e introdução a
bases de dicionário / Constraints Nomeadas x Dicionário
de Dados / Aprofundando com constrints - Querys de
Dicionário
Uma CHAVE é uma CONSTRAINT (REGRA). A
CHAVE é uma CONSTRAINT de integridade
referencial. A PRIMARY KEY garante que nosso
registro seja único e não se repita e a
FOREIGN KEY vai garantir que não tenhamos
registros em uma tabela sem referencia em outra.
A FOREIGN KEY precisa ter sua referencia na PRIMARY KEY que ela aponta, assim a integridade referencial exige que haja a PRIMARY KEY quando ela é informada.
Quando criamos as FOREIGN KEYS durante a criação de tabelas o SQL gera nomes automáticos para a CONSTRAINT dessas chaves. Podemos verificar esses nomes com o comando:
SHOW CREATE TABLE tabela
Quando instalamos o MySQL ele cria tres BDs: information_schema, mysql e performance_schema. Esses BDs são bancos do sistema e dentro deles nós temos os dicionários de dados.
As CONSTRAINTS criadas depois da criação das tabelas permite que criemos relacionamentos em referencias circularares. Isso permite também organizar o script de modo a criar primeiro todas as tabelas (CREATE TABLE) e depois as CONSTRAINTS (ALTER TABLE).
Para exemplificar esse processo vejamos o script abaixo que cria duas tabelas e aplica as CONSTRAINTS de chaves após a criação. Note que as colunas de chaves são criadas na tabela mas as atribuições de chave não.
Ao criar as tabelas com as CONSTRAINTS podemos verificar na estrutura da tabela com o SHOW CREATE TABLE o nome que definimos para a FOREIGN KEY:
Nem sempre é possível verificar as tabelas com comandos como o SHOW TABLES. Para isso precisamos saber consultar o Dicionário de Dados. O Dicionário de Dados armazena o Meta Dado das tabelas criadas.
Como dito anteriormente os Bancos de Dados information_schema, mysql e performance_schema são criados pelo sistema e neles que são armazenados todos os dados dos Dicionários de Dados.
Cada um destes bancos possi diversas tabelas com as informações do sistema e dos bancos armazenados.
O BD information_schema possui diversas tabelas entre elas a que estamos procurando nesse momento:
Tendo isso em mente podemos utilizar todos os comandos SQL para filtrar os dados que desejamos consultar. O retorno dessa projeção demonstra a importancia de controlar o nome das CONSTRAINTS e como isso facilita a pesquisa das variáveis do ambiente.
Com essas informações também podemos manipular as CONSTRAINTS (no caso as CHAVES criadas) de modo mais fácil.
A FOREIGN KEY precisa ter sua referencia na PRIMARY KEY que ela aponta, assim a integridade referencial exige que haja a PRIMARY KEY quando ela é informada.
Quando criamos as FOREIGN KEYS durante a criação de tabelas o SQL gera nomes automáticos para a CONSTRAINT dessas chaves. Podemos verificar esses nomes com o comando:
SHOW CREATE TABLE tabela
TIMES | CREATE TABLE `TIMES` (
`IDTIME` int(11) NOT NULL AUTO_INCREMENT,
`NOMETIME` varchar(30) DEFAULT NULL,
`ID_JOGADOR` int(11) DEFAULT NULL,
PRIMARY KEY (`IDTIME`),
KEY `ID_JOGADOR` (`ID_JOGADOR`),
CONSTRAINT `TIMES_ibfk_1` FOREIGN KEY (`ID_JOGADOR`) REFERENCES `JOGADOR` (`IDJOGADOR`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8
Para evitar esses nomes aleatórios devemos criar as
chaves após a criação das tabelas. A importancia de
controlar os nomes dessas chaves está no dicionário de
dados. Todos os elementos do BD (tabelas, views,
procedures) bem como as chaves são armazenadas no
dicionário. Daí a importancia de saber manipulá-lo e de
ter o controle sobre os nomes dos elementos. `IDTIME` int(11) NOT NULL AUTO_INCREMENT,
`NOMETIME` varchar(30) DEFAULT NULL,
`ID_JOGADOR` int(11) DEFAULT NULL,
PRIMARY KEY (`IDTIME`),
KEY `ID_JOGADOR` (`ID_JOGADOR`),
CONSTRAINT `TIMES_ibfk_1` FOREIGN KEY (`ID_JOGADOR`) REFERENCES `JOGADOR` (`IDJOGADOR`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8
Quando instalamos o MySQL ele cria tres BDs: information_schema, mysql e performance_schema. Esses BDs são bancos do sistema e dentro deles nós temos os dicionários de dados.
As CONSTRAINTS criadas depois da criação das tabelas permite que criemos relacionamentos em referencias circularares. Isso permite também organizar o script de modo a criar primeiro todas as tabelas (CREATE TABLE) e depois as CONSTRAINTS (ALTER TABLE).
Para exemplificar esse processo vejamos o script abaixo que cria duas tabelas e aplica as CONSTRAINTS de chaves após a criação. Note que as colunas de chaves são criadas na tabela mas as atribuições de chave não.
CREATE TABLE CLIENTE(
IDCLIENTE INT,
NOME VARCHAR(30) NOT NULL
);
CREATE TABLE TELEFONE(
IDTELEFONE INT,
TIPO CHAR(3) NOT NULL,
NUMERO VARCHAR(10) NOT NULL,
ID_CLIENTE INT
);
ALTER TABLE CLIENTE ADD CONSTRAINT PK_CLIENTE
PRIMARY KEY(IDCLIENTE);
ALTER TABLE TELEFONE ADD CONSTRAINT FK_CLIENTE_TELEFONE
FOREIGN KEY(ID_CLIENTE) REFERENCES CLIENTE(IDCLIENTE);
IDCLIENTE INT,
NOME VARCHAR(30) NOT NULL
);
CREATE TABLE TELEFONE(
IDTELEFONE INT,
TIPO CHAR(3) NOT NULL,
NUMERO VARCHAR(10) NOT NULL,
ID_CLIENTE INT
);
ALTER TABLE CLIENTE ADD CONSTRAINT PK_CLIENTE
PRIMARY KEY(IDCLIENTE);
ALTER TABLE TELEFONE ADD CONSTRAINT FK_CLIENTE_TELEFONE
FOREIGN KEY(ID_CLIENTE) REFERENCES CLIENTE(IDCLIENTE);
Note que não foi criada a PRIMARY KEY para a
tabela TELEFONE ne incluido
AUTO_INCREMENT para as colunas de ID
Ao criar as tabelas com as CONSTRAINTS podemos verificar na estrutura da tabela com o SHOW CREATE TABLE o nome que definimos para a FOREIGN KEY:
TELEFONE | CREATE TABLE `TELEFONE` (
`IDTELEFONE` int(11) DEFAULT NULL,
`TIPO` char(3) NOT NULL,
`NUMERO` varchar(10) NOT NULL,
`ID_CLIENTE` int(11) DEFAULT NULL,
KEY `FK_CLIENTE_TELEFONE` (`ID_CLIENTE`),
CONSTRAINT `FK_CLIENTE_TELEFONE` FOREIGN KEY (`ID_CLIENTE`) REFERENCES `CLIENTE` (`IDCLIENTE`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
`IDTELEFONE` int(11) DEFAULT NULL,
`TIPO` char(3) NOT NULL,
`NUMERO` varchar(10) NOT NULL,
`ID_CLIENTE` int(11) DEFAULT NULL,
KEY `FK_CLIENTE_TELEFONE` (`ID_CLIENTE`),
CONSTRAINT `FK_CLIENTE_TELEFONE` FOREIGN KEY (`ID_CLIENTE`) REFERENCES `CLIENTE` (`IDCLIENTE`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
Nem sempre é possível verificar as tabelas com comandos como o SHOW TABLES. Para isso precisamos saber consultar o Dicionário de Dados. O Dicionário de Dados armazena o Meta Dado das tabelas criadas.
Como dito anteriormente os Bancos de Dados information_schema, mysql e performance_schema são criados pelo sistema e neles que são armazenados todos os dados dos Dicionários de Dados.
Cada um destes bancos possi diversas tabelas com as informações do sistema e dos bancos armazenados.
O BD information_schema possui diversas tabelas entre elas a que estamos procurando nesse momento:
USE information_schema;
SHOW DATABASES;
DESC TABLE_CONSTRAINTS;
SELECT CONSTRAINT_SCHEMA AS 'BANCO',
TABLE_NAME AS 'TABELA',
CONSTRAINT_TYPE AS 'TIPO'
FROM TABLE_CONSTRAINTS;
O retorno dessa projeção mostra todas as chaves de
CONSTRAINT criadas em todas as tabelas dos BDs do
sistema. SHOW DATABASES;
DESC TABLE_CONSTRAINTS;
SELECT CONSTRAINT_SCHEMA AS 'BANCO',
TABLE_NAME AS 'TABELA',
CONSTRAINT_TYPE AS 'TIPO'
FROM TABLE_CONSTRAINTS;
Tendo isso em mente podemos utilizar todos os comandos SQL para filtrar os dados que desejamos consultar. O retorno dessa projeção demonstra a importancia de controlar o nome das CONSTRAINTS e como isso facilita a pesquisa das variáveis do ambiente.
Com essas informações também podemos manipular as CONSTRAINTS (no caso as CHAVES criadas) de modo mais fácil.
/* Selecionando a chave na tabela de CONSTRAINTS
com filtro */
SELECT CONSTRAINT_SCHEMA AS 'BANCO',
TABLE_NAME AS 'TABELA',
CONSTRAINT_TYPE AS 'TIPO',
CONSTRAINT_NAME AS 'NOME DA CHAVE'
FROM TABLE_CONSTRAINTS
WHERE CONSTRAINT_SCHEMA LIKE 'cursoSQLAula73' AND CONSTRAINT_TYPE='FOREIGN KEY';
| BANCO | TABELA | TIPO | NOME DA CHAVE |
| cursoSQLAula73 | TELEFONE | FOREIGN KEY | FK_CLIENTE_TELEFONE |
USE cursoSQLAula73;
ALTER TABLE TELEFONE
DROP FOREIGN KEY FK_CLIENTE_TELEFONE;
ALTER TABLE TELEFONE ADD CONSTRAINT FK_CLIENTE_TELEFONE
FOREIGN KEY(ID_CLIENTE) REFERENCES CLIENTE(IDCLIENTE);
Acima deletamos a FOREIGN KEY da tabela
TELEFONE e em seguida recriamos a chave. Isso é
útil para inclusões de dados em massa pois quando temos
que montar uma tabela de dados com
FOREIGN KEYS, durante a inserção de dados temos
o teste referencial de todos os dados inseridos. Isso
faz com que o processamento seja muito demorado,
portanto desabilitamos a
FOREIGN KEY momentaneamente enquanto inserimos
os dados na tabela e após isso recriamos a chave. Tudo
isso é feito mais facilmente utilizando as CONSTRAINTS
nomeadas.
SELECT CONSTRAINT_SCHEMA AS 'BANCO',
TABLE_NAME AS 'TABELA',
CONSTRAINT_TYPE AS 'TIPO',
CONSTRAINT_NAME AS 'NOME DA CHAVE'
FROM TABLE_CONSTRAINTS
WHERE CONSTRAINT_SCHEMA LIKE 'cursoSQLAula73' AND CONSTRAINT_TYPE='FOREIGN KEY';
| BANCO | TABELA | TIPO | NOME DA CHAVE |
| cursoSQLAula73 | TELEFONE | FOREIGN KEY | FK_CLIENTE_TELEFONE |
USE cursoSQLAula73;
ALTER TABLE TELEFONE
DROP FOREIGN KEY FK_CLIENTE_TELEFONE;
ALTER TABLE TELEFONE ADD CONSTRAINT FK_CLIENTE_TELEFONE
FOREIGN KEY(ID_CLIENTE) REFERENCES CLIENTE(IDCLIENTE);
Seção 18 - Aprendeu? Saiu o sistema do Seu José
Aula 76 - O sistema do Seu José - A oficina
Sr.José quer modernizar a sua oficina, e por
enquanto, cadastrar os carros que entram para
realizar serviços e os seus respectivos donos.
Sr.José mencionou que cada cliente possui apenas um
carro. Um carro possui uma marca. Sr. José também
quer saber todas as cores dos carros para ter ideia
de qual tinta comprar, e informa que um carro pode
ter mais de uma cor. Sr. José necessita armazenar os
telefones dos clientes, mas não quer que eles sejam
obrigatórios.
Meu desenvolvimento não levou algumas coisas em
consideração, como uma tabela para MARCA (pensei
no assunto porém como não haviam mais dados para o
CARRO criei isso como um atributo). No mais devo lembrar de criar os campos das chaves no MODELO LÓGICO.
Aula 77 a 78 - Correção / Continuação da correção e
...mais tarefas!
Como dito anteriormente o MODELO LOGICO que eu
fiz ficou diferente da resolução. Primeiro porque não
coloquei as chaves no modelo e segundo por que não criei
a entidade MARCA. Além disso o relacionamento
entre CARROS e CORES é n x n e
avança para um sistema que não foi explicado (será
criada uma TABELA ASSOCIATIVA para a ligação
entre as duas entidades).
Para a criação das tabelas na resolução foram incluidas as PRIMARY KEYS diretamente nas tabelas diferente do que foi explicado anteriormente. Outro ponto é que foi feito o AUTO_INCREMENT diretamente nas tabelas.
Com relação a definição dos atributos das tabelas, devemos sempre nos atentar a dados do tipo UNIQUE. O UNIQUE além de ser utilizado para determinar a obrigatorioedade ou não de um relacionamento também deve ser utilizado como proteção de inserção de dados na terceira camada da aplicação. Uma aplicação é composta por três camadas, sendo a primeira a camada de front-end onde fazemos as primeiras definições de validação (com JS), a segunda camada de aplicação onde fazemos a segunda validação (como PHP, JAVA, Ruby, etc) e por fim a terceira camada que é o BD, onde podemos definir campos como UNIQUE ou NOT NULL de modo a evitar a inconsistencia caso passem as informações até aqui.
A TABELA ASSOCIATIVA é criada a partir de duas PRIMARY KEY, ou seja, ela cria uma PRIMARY KEY própria que é uma combinação das chaves recebidas:
IF condição THEN instruções ELSE instruções END IF;
Com isso criei as seguintes PROCEDURES para inserir os dados:
Por fim fiz uma projeção com todos os dados inclusive com os dados da TABELA ASSOCIATIVA:
Para a criação das tabelas na resolução foram incluidas as PRIMARY KEYS diretamente nas tabelas diferente do que foi explicado anteriormente. Outro ponto é que foi feito o AUTO_INCREMENT diretamente nas tabelas.
Com relação a definição dos atributos das tabelas, devemos sempre nos atentar a dados do tipo UNIQUE. O UNIQUE além de ser utilizado para determinar a obrigatorioedade ou não de um relacionamento também deve ser utilizado como proteção de inserção de dados na terceira camada da aplicação. Uma aplicação é composta por três camadas, sendo a primeira a camada de front-end onde fazemos as primeiras definições de validação (com JS), a segunda camada de aplicação onde fazemos a segunda validação (como PHP, JAVA, Ruby, etc) e por fim a terceira camada que é o BD, onde podemos definir campos como UNIQUE ou NOT NULL de modo a evitar a inconsistencia caso passem as informações até aqui.
A TABELA ASSOCIATIVA é criada a partir de duas PRIMARY KEY, ou seja, ela cria uma PRIMARY KEY própria que é uma combinação das chaves recebidas:
CREATE TABLE CARRO_COR(
ID_CARRO INT,
ID_COR INT,
PRIMARY KEY(ID_CARRO,ID_COR)
);
Na sequencia as CONSTRAINTS que eu criei estão
corretas. A única que ficou faltando foi a da
TABELA ASSOCIATIVA. Nesse caso devemos criar
duas FOREIGN KEYS. Uma Chave pode ser ao mesmo
tempo PRIMARY e FOREIGN.
ID_CARRO INT,
ID_COR INT,
PRIMARY KEY(ID_CARRO,ID_COR)
);
ALTER TABLE CARRO_COR
ADD CONSTRAINT FK_COR
FOREIGN KEY(ID_COR)
REFERENCES CORES(IDCOR);
ALTER TABLE CARRO_COR
ADD CONSTRAINT FK_CARRO
FOREIGN KEY(ID_CARRO)
REFERENCES CARROS(IDCARRO);
Feito isso foi solicitado que fossem feitas inclusões de
dados no banco. Essa parte não tem correção mas criei
PROCEDURES para incluir o máximo de dados
possíveis. Como queria que fossem verificados se
existiam dados na tabela de MARCAS e
CORES antes de inclui-las pesquisei como utilizar
condicionais no MySQL. O resultado da pesquisa está na
página
MySQL Documentation . A estrutura IF no MySQL é: ADD CONSTRAINT FK_COR
FOREIGN KEY(ID_COR)
REFERENCES CORES(IDCOR);
ALTER TABLE CARRO_COR
ADD CONSTRAINT FK_CARRO
FOREIGN KEY(ID_CARRO)
REFERENCES CARROS(IDCARRO);
IF condição THEN instruções ELSE instruções END IF;
Com isso criei as seguintes PROCEDURES para inserir os dados:
DELIMITER #
CREATE PROCEDURE INSERT_CARRO_CLIENTE(V_MODELO VARCHAR(30), V_PLACA VARCHAR(7), V_MARCA VARCHAR(30), V_NOME VARCHAR(30), V_SEXO CHAR(1), V_CPF VARCHAR(11), V_TIPO CHAR(3), V_NUMERO VARCHAR(10) )
BEGIN
IF EXISTS (SELECT IDMARCA FROM MARCA WHERE MARCA LIKE V_MARCA) THEN
INSERT INTO CARROS VALUES(NULL, V_MODELO, V_PLACA,
(SELECT IDMARCA FROM MARCA WHERE MARCA LIKE V_MARCA));
INSERT INTO CLIENTES VALUES(NULL, V_NOME, V_SEXO, V_CPF,
(SELECT IDCARRO FROM CARROS WHERE PLACA=V_PLACA));
INSERT INTO TELEFONE VALUES(NULL, V_TIPO, V_NUMERO,
(SELECT IDCLIENTE FROM CLIENTES WHERE CPF=V_CPF));
ELSE
INSERT INTO MARCA VALUES(NULL, V_MARCA);
INSERT INTO CARROS VALUES(NULL, V_MODELO, V_PLACA,
(SELECT IDMARCA FROM MARCA WHERE MARCA LIKE V_MARCA));
INSERT INTO CLIENTES VALUES(NULL, V_NOME, V_SEXO, V_CPF,
(SELECT IDCARRO FROM CARROS WHERE PLACA=V_PLACA));
INSERT INTO TELEFONE VALUES(NULL, V_TIPO, V_NUMERO,
(SELECT IDCLIENTE FROM CLIENTES WHERE CPF=V_CPF));
END IF;
END
#
DELIMITER ;
DELIMITER #
CREATE PROCEDURE INSERT_COR_CARRO(V_ID_CARRO INT, V_COR VARCHAR(30))
BEGIN
IF EXISTS (SELECT IDCOR FROM CORES WHERE COR LIKE V_COR) THEN
INSERT INTO CARRO_COR VALUES(V_ID_CARRO,
(SELECT IDCOR FROM CORES WHERE COR LIKE V_COR));
ELSE
INSERT INTO CORES VALUES(NULL, V_COR);
INSERT INTO CARRO_COR VALUES(V_ID_CARRO,
(SELECT IDCOR FROM CORES WHERE COR LIKE V_COR));
END IF;
END
#
DELIMITER ;
DELIMITER #
CREATE PROCEDURE INSERT_FONE_CLIENTE(V_TIPO CHAR(3), V_NUMERO VARCHAR(10), V_NOME VARCHAR(30))
BEGIN
INSERT INTO TELEFONE VALUES(NULL,V_TIPO, V_NUMERO,
(SELECT IDCLIENTE FROM CLIENTES WHERE NOME=V_NOME));
END
#
DELIMITER ;
CREATE PROCEDURE INSERT_CARRO_CLIENTE(V_MODELO VARCHAR(30), V_PLACA VARCHAR(7), V_MARCA VARCHAR(30), V_NOME VARCHAR(30), V_SEXO CHAR(1), V_CPF VARCHAR(11), V_TIPO CHAR(3), V_NUMERO VARCHAR(10) )
BEGIN
IF EXISTS (SELECT IDMARCA FROM MARCA WHERE MARCA LIKE V_MARCA) THEN
INSERT INTO CARROS VALUES(NULL, V_MODELO, V_PLACA,
(SELECT IDMARCA FROM MARCA WHERE MARCA LIKE V_MARCA));
INSERT INTO CLIENTES VALUES(NULL, V_NOME, V_SEXO, V_CPF,
(SELECT IDCARRO FROM CARROS WHERE PLACA=V_PLACA));
INSERT INTO TELEFONE VALUES(NULL, V_TIPO, V_NUMERO,
(SELECT IDCLIENTE FROM CLIENTES WHERE CPF=V_CPF));
ELSE
INSERT INTO MARCA VALUES(NULL, V_MARCA);
INSERT INTO CARROS VALUES(NULL, V_MODELO, V_PLACA,
(SELECT IDMARCA FROM MARCA WHERE MARCA LIKE V_MARCA));
INSERT INTO CLIENTES VALUES(NULL, V_NOME, V_SEXO, V_CPF,
(SELECT IDCARRO FROM CARROS WHERE PLACA=V_PLACA));
INSERT INTO TELEFONE VALUES(NULL, V_TIPO, V_NUMERO,
(SELECT IDCLIENTE FROM CLIENTES WHERE CPF=V_CPF));
END IF;
END
#
DELIMITER ;
DELIMITER #
CREATE PROCEDURE INSERT_COR_CARRO(V_ID_CARRO INT, V_COR VARCHAR(30))
BEGIN
IF EXISTS (SELECT IDCOR FROM CORES WHERE COR LIKE V_COR) THEN
INSERT INTO CARRO_COR VALUES(V_ID_CARRO,
(SELECT IDCOR FROM CORES WHERE COR LIKE V_COR));
ELSE
INSERT INTO CORES VALUES(NULL, V_COR);
INSERT INTO CARRO_COR VALUES(V_ID_CARRO,
(SELECT IDCOR FROM CORES WHERE COR LIKE V_COR));
END IF;
END
#
DELIMITER ;
DELIMITER #
CREATE PROCEDURE INSERT_FONE_CLIENTE(V_TIPO CHAR(3), V_NUMERO VARCHAR(10), V_NOME VARCHAR(30))
BEGIN
INSERT INTO TELEFONE VALUES(NULL,V_TIPO, V_NUMERO,
(SELECT IDCLIENTE FROM CLIENTES WHERE NOME=V_NOME));
END
#
DELIMITER ;
Por fim fiz uma projeção com todos os dados inclusive com os dados da TABELA ASSOCIATIVA:
SELECT CAR.IDCARRO, CAR.MODELO, CAR.PLACA,
M.MARCA, C.COR, CLI.NOME, CLI.SEXO, CLI.CPF,
T.TIPO, T.NUMERO
FROM CARROS AS CAR
INNER JOIN MARCA AS M
ON M.IDMARCA = CAR.ID_MARCA
INNER JOIN CLIENTES AS CLI
ON CAR.IDCARRO = CLI.ID_CARRO
LEFT JOIN TELEFONE AS T
ON T.ID_CLIENTE = CLI.IDCLIENTE
LEFT JOIN CARRO_COR
ON CARRO_COR.ID_CARRO = CAR.IDCARRO
LEFT JOIN CORES AS C
ON CARRO_COR.ID_COR = C.IDCOR
ORDER BY CAR.IDCARRO;
FROM CARROS AS CAR
INNER JOIN MARCA AS M
ON M.IDMARCA = CAR.ID_MARCA
INNER JOIN CLIENTES AS CLI
ON CAR.IDCARRO = CLI.ID_CARRO
LEFT JOIN TELEFONE AS T
ON T.ID_CLIENTE = CLI.IDCLIENTE
LEFT JOIN CARRO_COR
ON CARRO_COR.ID_CARRO = CAR.IDCARRO
LEFT JOIN CORES AS C
ON CARRO_COR.ID_COR = C.IDCOR
ORDER BY CAR.IDCARRO;
Seção 19 - Automatizando as coisas - Triggers
Aula 79 a 80 - Introdução às fantásticas Triggers / Agora é pra valer! Trigger na práticaA estrutura básica de uma TRIGGER é a seguinte:
CREATE TRIGGER NOME
(BEFORE/AFTER) (INSERT/DELETE/UPDATE) ON TABELA
FOR EACH ROW
BEGIN
COMANDOS SQL
END
Desse modo a TRIGGER pode ser disparada
BEFORE(ANTES) ou
AFTER(DEPOIS) de um comando de
DML
INSERT, DELETE ou UPDATE.
(BEFORE/AFTER) (INSERT/DELETE/UPDATE) ON TABELA
FOR EACH ROW
BEGIN
COMANDOS SQL
END
O case sensitive do MySQL é definido pelo SO em que ele está instalado. Assim em sistemas Windows ele
Podemos consultar as TRIGGERS no dicionário de dados information_schema. Para trabalhar com TRIGGERS criamos duas tabelas, uma de USUARIO e uma para armazenar um backup de usuários BLP_USUARIO. Note que o campo de SENHA da tabela USUARIO não é incluida no backup por segurança e tem um tipo VARCHAR(100) pois deve ser aramazenada em modo criptografado (por isso tantos caracteres).
Vamos criar uma TRIGGER que gravará os dados do usuário caso ele seja removido.
Podemos criar em cada tabela apenas uma TRIGGER para cada uma das condições (BEFORE INSERT/AFTER INSERT, BEFORE DELETE /AFTER DELETE, BEFORE UPDATE/AFTER UPDATE).
Os dados podem ser NEW ou OLD. Valores de inserção (INSERT) são NEW. Valores removidos (DELETE) são OLD. Já em comandos de UPDATE o valor que está sendo inserido é NEW e o valor que está sendo alterado é OLD.
Essa TRIGGER fica como segue:
DELIMITER $
CREATE TRIGGER BACKUP_USER
BEFORE DELETE ON USUARIO
FOR EACH ROW
BEGIN
INSERT INTO BKP_USUARIO VALUES
(NULL, OLD.IDUSUARIO, OLD.NOME, OLD.LOGIN);
END
$
DELIMITER ;
Criada essa TRIGGER temos o monitoramento do
DELETE na tabela USUARIO e seus dados são
automaticamente copiados para a tabela
BKP_USUARIO quando percebe um comando de
DELETE. CREATE TRIGGER BACKUP_USER
BEFORE DELETE ON USUARIO
FOR EACH ROW
BEGIN
INSERT INTO BKP_USUARIO VALUES
(NULL, OLD.IDUSUARIO, OLD.NOME, OLD.LOGIN);
END
$
DELIMITER ;
Para fazer a junção em uma tabela com AUTO RELACIONAMENTO precisamos criar um ALIAS para a referencia na mesma tabela para que o INNER JOIN consiga ligar a mesma tabela como se fossem duas tabelas.
Atenção sempre que for fazer a declaração do relacionamento no INNER JOIN...ON... pois a ordem dos elementos da junção é a chave para o resultado
Aula 81 - Triggers para bancos de backups / After,
Before, Insert, Delete ou Update? Os eventos de uma
trigger
Em BDs podemos fazer backups físicos (em fitas, rede,
hds, etc) ou lógicos (backup em outra tabela ou em outro
banco). Quando copiamos os dados em outra tabela (como
no exemplo anterior) não protegemos os dados em caso de
quebra no BD. Para isso podemos fazer a comunicação
entre dois bancos sendo um o espelho do outro. Podemos
fazer isso com TIGGERS.
Para essa comunicação devemos preceder o nome da tabela pelo nome do banco:
INSERT INTO nome_do_banco.nome_da_tabela VALUES(a,b,c);
Desse modo podemos fazer o backup através de uma TRIGGER que recupere os valores ANTES de INSERIR os dados em uma tabela e faça o INSERT na tabela backup. Como os valores são novos(inserção) utilizamos o comando NEW:
Em seguida criamos uma nova TRIGGER para tratar o DELETE de dados. Note que nesse caso apenas alteremos o método de disparo da TRIGGER e o dado que será tratado OLD:
Na TIGGER de INSERT estamos recuperando o valor com o BEFORE. Como recuperamos o valor ANTES de ele ser inserido na tabela o valor do IDPRODUTO ainda não foi criado pelo AUTO_INCREMENT e assim não é exportado para a tabela de backup. Podemos corrigir isso alterando o momento de acionar o TRIGGER para AFTER(depois da inserção).
Outro ponto é criar uma coluna para definir o que gerou a inserção do dado na tabela (INSERT ou DELETE). Para isso criamos uma nova coluna (eu criei duas uma para o evento e outra para armazenar a data e hora da ocorrencia) onde monitoramos qual evento gerou a entrada na tabela de backup.
Para essa comunicação devemos preceder o nome da tabela pelo nome do banco:
INSERT INTO nome_do_banco.nome_da_tabela VALUES(a,b,c);
Desse modo podemos fazer o backup através de uma TRIGGER que recupere os valores ANTES de INSERIR os dados em uma tabela e faça o INSERT na tabela backup. Como os valores são novos(inserção) utilizamos o comando NEW:
DELIMITER #
CREATE TRIGGER BACKUP_PRODUTO
BEFORE INSERT ON PRODUTO
FOR EACH ROW
BEGIN
INSERT INTO cursoSQLAula81BACKUP.BKP_PRODUTO VALUES(NULL,NEW.IDPRODUTO,NEW.NOME,NEW.VALOR);
END
#
DELIMITER ;
Com essa TRIGGER todos os dados que são inseridos
na tabela PRODUTO, são automaticamente inseridos
também na tabela BKP_PRODUTO localizada no banco
cursoSQLAula81BACKUP. CREATE TRIGGER BACKUP_PRODUTO
BEFORE INSERT ON PRODUTO
FOR EACH ROW
BEGIN
INSERT INTO cursoSQLAula81BACKUP.BKP_PRODUTO VALUES(NULL,NEW.IDPRODUTO,NEW.NOME,NEW.VALOR);
END
#
DELIMITER ;
Em seguida criamos uma nova TRIGGER para tratar o DELETE de dados. Note que nesse caso apenas alteremos o método de disparo da TRIGGER e o dado que será tratado OLD:
DELIMITER #
CREATE TRIGGER BACKUP_PRODUTO_DEL
BEFORE DELETE ON PRODUTO
FOR EACH ROW
BEGIN
INSERT INTO cursoSQLAula81BACKUP.BKP_PRODUTO VALUES(NULL,OLD.IDPRODUTO,OLD.NOME,OLD.VALOR);
END
#
DELIMITER ;
Utilizando a estrutura acima todos os dados inseridos e
deletados serão tranferidos para a tabela de backup.
Isso vai resultar em uma redundancia de dados. Temos
aqui dois pontos a corrigir. CREATE TRIGGER BACKUP_PRODUTO_DEL
BEFORE DELETE ON PRODUTO
FOR EACH ROW
BEGIN
INSERT INTO cursoSQLAula81BACKUP.BKP_PRODUTO VALUES(NULL,OLD.IDPRODUTO,OLD.NOME,OLD.VALOR);
END
#
DELIMITER ;
Na TIGGER de INSERT estamos recuperando o valor com o BEFORE. Como recuperamos o valor ANTES de ele ser inserido na tabela o valor do IDPRODUTO ainda não foi criado pelo AUTO_INCREMENT e assim não é exportado para a tabela de backup. Podemos corrigir isso alterando o momento de acionar o TRIGGER para AFTER(depois da inserção).
Outro ponto é criar uma coluna para definir o que gerou a inserção do dado na tabela (INSERT ou DELETE). Para isso criamos uma nova coluna (eu criei duas uma para o evento e outra para armazenar a data e hora da ocorrencia) onde monitoramos qual evento gerou a entrada na tabela de backup.
Aula 83 - Quem mexeu no meu dado? Auditando uma tabela
com trigger
Podemos criar TRIGGERS para auditar manipulações
de dados em uma tabela de backup utilizando o exemplo
acima. Isso pode ser feito armazenando, por exemplo, os
dados alterados (utilizando OLD e NEW), a
data e hora da alteração (utilizando a função
NOW()) e o usuário que fez a alteração
(utilizando a função CURRENT_USEER()).
Para isso criamos a seguinte tabela de backup (com as colunas de acordo com a proposta) e a seguinte TRIGGER de auditoria:
Para isso criamos a seguinte tabela de backup (com as colunas de acordo com a proposta) e a seguinte TRIGGER de auditoria:
CREATE DATABASE cursoSQLAula83BACKUP;
USE cursoSQLAula83BACKUP;
CREATE TABLE BKP_PRODUTO(
IDBKP INT PRIMARY KEY AUTO_INCREMENT,
IDPRODUTO INT,
NOME VARCHAR(30),
VALOR_ORIGINAL FLOAT(10,2),
VALOR_ALTERADO FLOAT(10,2),
DATA DATETIME,
USUARIO VARCHAR(30),
EVENTO CHAR(1)
);
DELIMITER #
CREATE TRIGGER AUDIT_PRODUTO
AFTER UPDATE ON PRODUTO
FOR EACH ROW
BEGIN
INSERT INTO cursoSQLAula83BACKUP.BKP_PRODUTO VALUES(NULL, OLD.IDPRODUTO, OLD.NOME, OLD.VALOR, NEW.VALOR, NOW(), CURRENT_USER() ,'U');
END
#
DELIMITER ;
USE cursoSQLAula83BACKUP;
CREATE TABLE BKP_PRODUTO(
IDBKP INT PRIMARY KEY AUTO_INCREMENT,
IDPRODUTO INT,
NOME VARCHAR(30),
VALOR_ORIGINAL FLOAT(10,2),
VALOR_ALTERADO FLOAT(10,2),
DATA DATETIME,
USUARIO VARCHAR(30),
EVENTO CHAR(1)
);
DELIMITER #
CREATE TRIGGER AUDIT_PRODUTO
AFTER UPDATE ON PRODUTO
FOR EACH ROW
BEGIN
INSERT INTO cursoSQLAula83BACKUP.BKP_PRODUTO VALUES(NULL, OLD.IDPRODUTO, OLD.NOME, OLD.VALOR, NEW.VALOR, NOW(), CURRENT_USER() ,'U');
END
#
DELIMITER ;
Seção 20 - Mais modelagem
Aula 84 a 85 - Eu e eu mesmo! O Autorelacionamento / Corrigindo o exercício
CREATE TABLE CURSOS(
IDCURSO INT PRIMARY KEY AUTO_INCREMENT,
NOME VARCHAR(30),
HORAS INT,
VALOR FLOAT(10,2),
ID_PREREQ INT
);
ALTER TABLE CURSOS ADD CONSTRAINT FK_PREREQ
FOREIGN KEY (ID_PREREQ) REFERENCES CURSOS(IDCURSO);
No exemplo utilizado em aula consideramos uma escola que
tenha cursos que sejam pre-requisitos para outros cursos
(então um curso que tenha outro curso da mesma tabela
como pre-requisito tem um auto relacionamento). IDCURSO INT PRIMARY KEY AUTO_INCREMENT,
NOME VARCHAR(30),
HORAS INT,
VALOR FLOAT(10,2),
ID_PREREQ INT
);
ALTER TABLE CURSOS ADD CONSTRAINT FK_PREREQ
FOREIGN KEY (ID_PREREQ) REFERENCES CURSOS(IDCURSO);
Importante ressaltar que no caso do exemplo não podemos incluir no campo ID_PREREQ a propriedade NOT NULL pois podemos ter cursos sem pre-requisitos que terão sua FOREIGN KEY como NULL. Para situações em que não queremos permitir o campo NULL podemos criar na tabela, antes de criar a CONSTRAINT valores do tipo 'SEM PRE REQ' (ou de forma mais genérica valores como 'NÃO SE APLICA' ou 'NÃO INFORMADO').
Para fazer projeções em tabelas com AUTO RELACIONAMENTO devemos fazer duas referencias para a mesma tabela utilizando ALIAS para criar a segunda referencia.
A sintaxe nesse caso fica como segue:
SELECT CURSOS.IDCURSO, CURSOS.NOME,
CURSOS.HORAS, CURSOS.VALOR, IFNULL(C.NOME,'SEM
REQ') FROM CURSOS
LEFT JOIN CURSOS AS C
ON C.IDCURSO = CURSOS.ID_PREREQ;
Nesse aula foi explicada a utilização do
LEFT JOIN para abranger na junção os itens do
conjunto de dados da esquerda (é possível também fazer
um RIGHT JOIN).
LEFT JOIN CURSOS AS C
ON C.IDCURSO = CURSOS.ID_PREREQ;
Seção 21 - Programe, programe
Aula 86 - Introdução aos cursoresQuando precisamos criar tabelas e fazer operações matemáticas com os dados para gerar campos com totais por exemplo, ao fazermos as operações em uma projeção temos as operações em tempo de execução. Os cursores fazem um loop na tabela e realizam as operações tornando a obtenção dos resultados mais rápida.
Um CURSOR é criado dentro de uma PROCEDURE e segue a mesma estrutura desta. O que o diferencia é a criação de variáveis, em especial a variável que recebe o vetor de dados, e as variáveis e lógica do LOOP que percorrerá os dados.
Para declarar variáveis no SQL utilizamos o comando DECLARE e a elas podemos atribuir qualquer tipo permitido no SQL.
Criada a procedure a estrutura de um CURSOR é a seguinte:
DELIMITER $
CREATE PROCEDURE INSEREDADOS()
BEGIN
DECLARE FIM INT DEFAULT 0;
DECLARE VAR1, VAR2, VAR3, VTOTAL, VMEDIA INT;
DECLARE VNOME VARCHAR(50);
DECLARE REG CURSOR FOR(
SELECT NOME, JAN, FEV, MAR FROM VENDEDORES
);
DECLARE CONTINUE HANDLER FOR NOT FOUND SET FIM = 1;
OPEN REG;
REPEAT
FETCH REG INTO VNOME, VAR1, VAR2, VAR3;
IF NOT FIM THEN
SET VTOTAL = VAR1 + VAR2 + VAR3;
SET VMEDIA = VTOTAL / 3;
INSERT INTO VEND_TOTAL VALUES(VNOME, VAR1, VAR2, VAR3, VTOTAL, VMEDIA);
END IF;
UNTIL FIM END REPEAT;
CLOSE REG;
END
$
DELIMITER ;
Após a criação da PROCEDURE iniciamos criando
uma variável para monitorar o fim do loop. A essa
variável atribuimos o valor '0'. CREATE PROCEDURE INSEREDADOS()
BEGIN
DECLARE FIM INT DEFAULT 0;
DECLARE VAR1, VAR2, VAR3, VTOTAL, VMEDIA INT;
DECLARE VNOME VARCHAR(50);
DECLARE REG CURSOR FOR(
SELECT NOME, JAN, FEV, MAR FROM VENDEDORES
);
DECLARE CONTINUE HANDLER FOR NOT FOUND SET FIM = 1;
OPEN REG;
REPEAT
FETCH REG INTO VNOME, VAR1, VAR2, VAR3;
IF NOT FIM THEN
SET VTOTAL = VAR1 + VAR2 + VAR3;
SET VMEDIA = VTOTAL / 3;
INSERT INTO VEND_TOTAL VALUES(VNOME, VAR1, VAR2, VAR3, VTOTAL, VMEDIA);
END IF;
UNTIL FIM END REPEAT;
CLOSE REG;
END
$
DELIMITER ;
Em seguida criamos as variáveis que precisamos para a rotina que iremos criar. Podemos agrupar variáveis que receberão o mesmo tipo em um mesmo DECLARE.
No exemplo em seguida criamos o CURSOR que receberá a rotina que será executada no BD (no exemplo uma projeção dos dados da tabela).
A linha a seguir é padrão para o CURSOR:
DECLARE CONTINUE HANDLER FOR NOT FOUND SET FIM = 1;
Ela altera o valor da variável FIM para 1 quando o valor da leitura na tabela dor igual a NOT FOUND.
A seguir iniciamos a variável do CURSOR com o comando OPEN.
Em seguida iniciamos um bloco de repetição com o REPEAT e iniciamos o processamento dos dados na memória. Iniciamos fazendo o FETCH na variável onde está o CURSOR e tranferindo os dados para as variáveis. Em segida testamos se a variável FIM foi setada e caso contrário executamos a instrução necessária.
Essa instrução será executada até que o HANDLER altere o valor de FIM para '1' conforme a linha:
UNTIL FIM END REPEAT
Finalizado o processo devemos fechar a variável do CURSOR no caso com CLOSE REG.
Seção 22 - Normalizando mais
Aula 88 - 2 e 3 formas normaisUm campo não pode ser divisível (o campo não pode ser multi valorado);
Um campo não pode ser vetorizado;
temos que ter uma PRIMARY KEY que faz com que cada registro seja único.
A segunda e a terceira formas normais tratam dos casos em que temos chaves compostas.
Em determinadas ocasiões o relacionameto entre tabelas através de uma tabela associativa pode gerar combinações de chaves repetidas (no exemplo foi utilizado um relacionamento ternário entre tabelas PACIENTE, MEDICO, HOSPITAL. Nesse caso um PACIENTE pode passar mais que uma vez com o mesmo MEDICO no mesmo HOSPITAL. A chave gerada pelas chaves primárias desses tres elementos resultará em uma PK repetida).
Nesse caso precisamos criar uma PRIMARY KEY na tabela de associação que receberá tres FOREIGN KEYS que serã apenas valores de ligação e não farão a composição da PK.
Para a SEGUNDA FORMA NORMAL qualquer campo não chave
Já a TERCEIRA FORMA NORMAL é uma dependencia transitiva. No exemplo a INTERNACAO não depende de todas as chaves (PACIENTE, MEDICO, HOSPITAL) mas depende do DIAGNOSTICO. Assim campos não chave que depende de outros campos não chave devem ser colocados em uma nova tabela.
Aula 89 a 90 - Vamos praticar? Parte 1 / Criando as
Constraints
Iniciamos criando as tabelas segundo o Modelo Lógico
definido acima. Quanto a algumas ideias como criar uma
tabela de ESPECIALIDADE para os médicos devemos
sempre pensar que quanto mais tabelas mais
JOINs deveremos fazer. Assim é preciso pensar
quando é necessário desmembrar tabelas e quando deixar
certos campos em uma única tabela.
A criação das tabelas não tem nenhum segredo. A única observação é quanto a FK ID_CONSULTA que foi definida como UNIQUE.
Em seguida criamos as CONSTRAINTS de FOREIGN KEY, também sem novidades.
A criação das tabelas não tem nenhum segredo. A única observação é quanto a FK ID_CONSULTA que foi definida como UNIQUE.
Em seguida criamos as CONSTRAINTS de FOREIGN KEY, também sem novidades.